






- Bandwidth estimation (BWE) and congestion control play an important role in delivering high-quality real-time communication (RTC) across Meta’s family of apps.
- We’ve adopted a machine learning (ML)-based approach that allows us to solve networking problems holistically across cross-layers such as BWE, network resiliency, and transport.
- We’re sharing our experiment results from this approach, some of the challenges we encountered during execution, and learnings for new adopters.
Our existing bandwidth estimation (BWE) module at Meta is based on WebRTC’s Google Congestion Controller (GCC). We have made several improvements through parameter tuning, but this has resulted in a more complex system, as shown in Figure 1.
One challenge with the tuned congestion control (CC)/BWE algorithm was that it had multiple parameters and actions that were dependent on network conditions. For example, there was a trade-off between quality and reliability; improving quality for high-bandwidth users often led to reliability regressions for low-bandwidth users, and vice versa, making it challenging to optimize the user experience for different network conditions.
Additionally, we noticed some inefficiencies in regards to improving and maintaining the module with the complex BWE module:
- Due to the absence of realistic network conditions during our experimentation process, fine-tuning the parameters for user clients necessitated several attempts.
- Even after the rollout, it wasn’t clear if the optimized parameters were still applicable for the targeted network types.
- This resulted in complex code logics and branches for engineers to maintain.
To solve these inefficiencies, we developed a machine learning (ML)-based, network-targeting approach that offers a cleaner alternative to hand-tuned rules. This approach also allows us to solve networking problems holistically across cross-layers such as BWE, network resiliency, and transport.
Network characterization
An ML model-based approach leverages time series data to improve the bandwidth estimation by using offline parameter tuning for characterized network types.
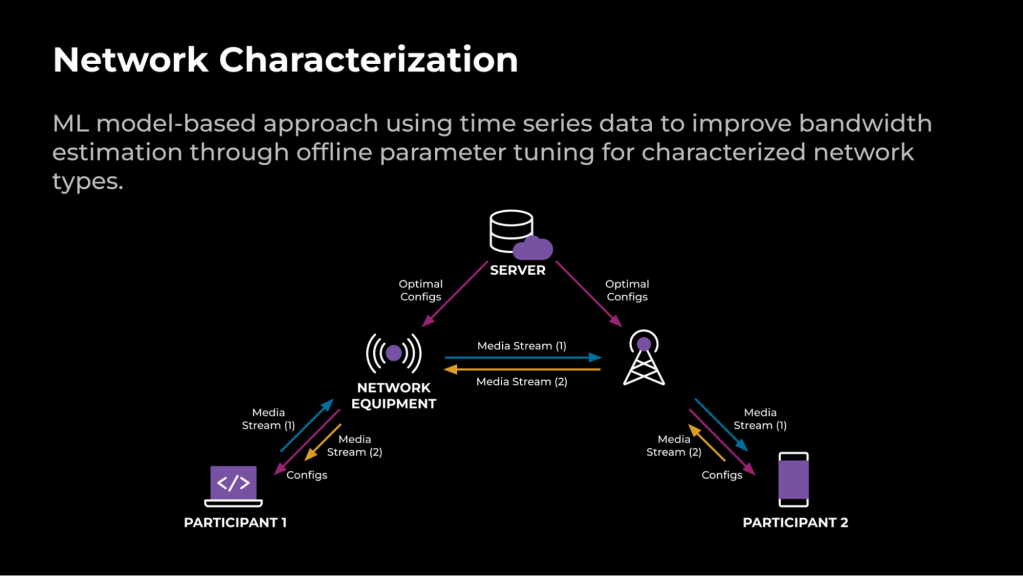
For an RTC call to be completed, the endpoints must be connected to each other through network devices. The optimal configs that have been tuned offline are stored on the server and can be updated in real-time. During the call connection setup, these optimal configs are delivered to the client. During the call, media is transferred directly between the endpoints or through a relay server. Depending on the network signals collected during the call, an ML-based approach characterizes the network into different types and applies the optimal configs for the detected type.
Figure 2 illustrates an example of an RTC call that’s optimized using the ML-based approach.
Model learning and offline parameter tuning
On a high level, network characterization consists of two main components, as shown in Figure 3. The first component is offline ML model learning using ML to categorize the network type (random packet loss versus bursty loss). The second component uses offline simulations to tune parameters optimally for the categorized network type.
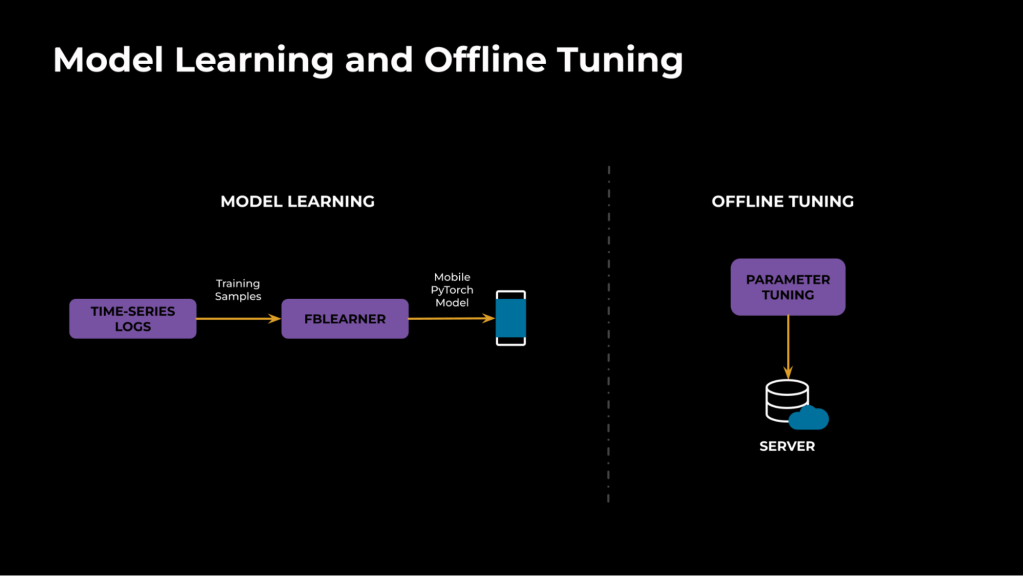
For model learning, we leverage the time series data (network signals and non-personally identifiable information, see Figure 6, below) from production calls and simulations. Compared to the aggregate metrics logged after the call, time series captures the time-varying nature of the network and dynamics. We use FBLearner, our internal AI stack, for the training pipeline and deliver the PyTorch model files on demand to the clients at the start of the call.
For offline tuning, we use simulations to run network profiles for the detected types and choose the optimal parameters for the modules based on improvements in technical metrics (such as quality, freeze, and so on.).
Model architecture
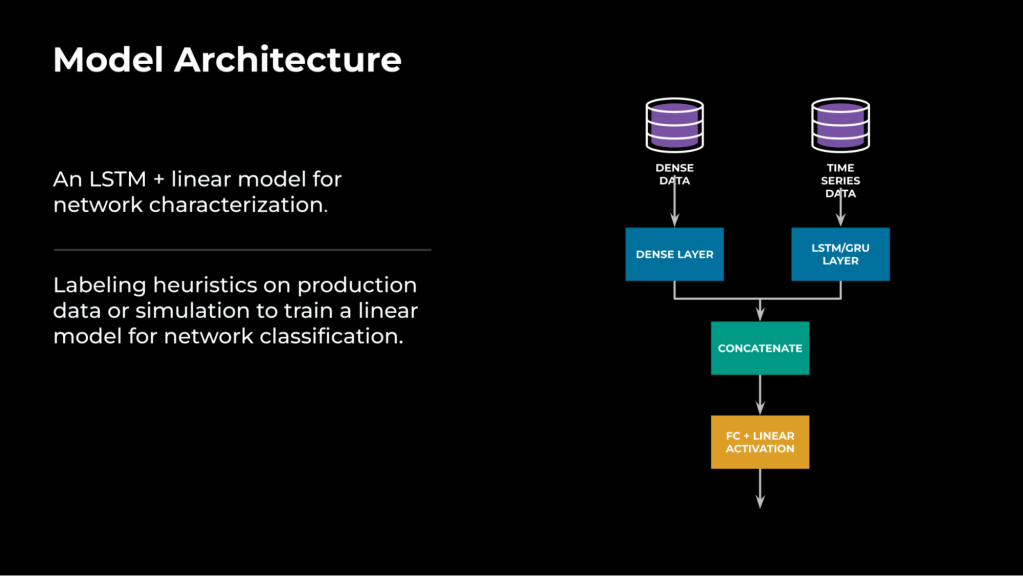
From our experience, we’ve found that it’s necessary to combine time series features with non-time series (i.e., derived metrics from the time window) for a highly accurate modeling.
To handle both time series and non-time series data, we’ve designed a model architecture that can process input from both sources.
The time series data will pass through a long short-term memory (LSTM) layer that will convert time series input into a one-dimensional vector representation, such as 16×1. The non-time series data or dense data will pass through a dense layer (i.e., a fully connected layer). Then the two vectors will be concatenated, to fully represent the network condition in the past, and passed through a fully connected layer again. The final output from the neural network model will be the predicted output of the target/task, as shown in Figure 4.
Use case: Random packet loss classification
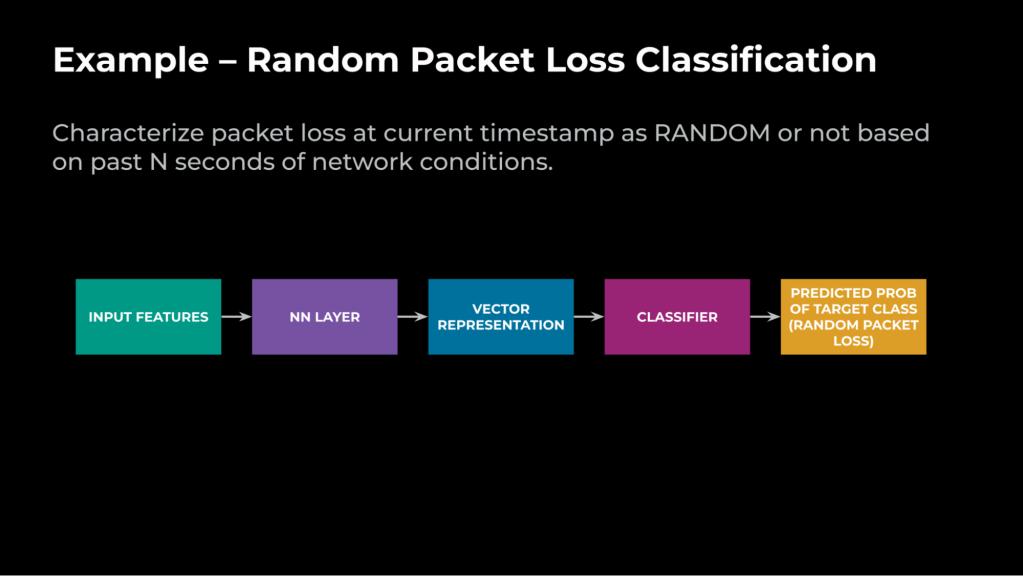
Let’s consider the use case of categorizing packet loss as either random or congestion. The former loss is due to the network components, and the latter is due to the limits in queue length (which are delay dependent). Here is the ML task definition:
Given the network conditions in the past N seconds (10), and that the network is currently incurring packet loss, the goal is to characterize the packet loss at the current timestamp as RANDOM or not.
Figure 5 illustrates how we leverage the architecture to achieve that goal:
Time series features
We leverage the following time series features gathered from logs:
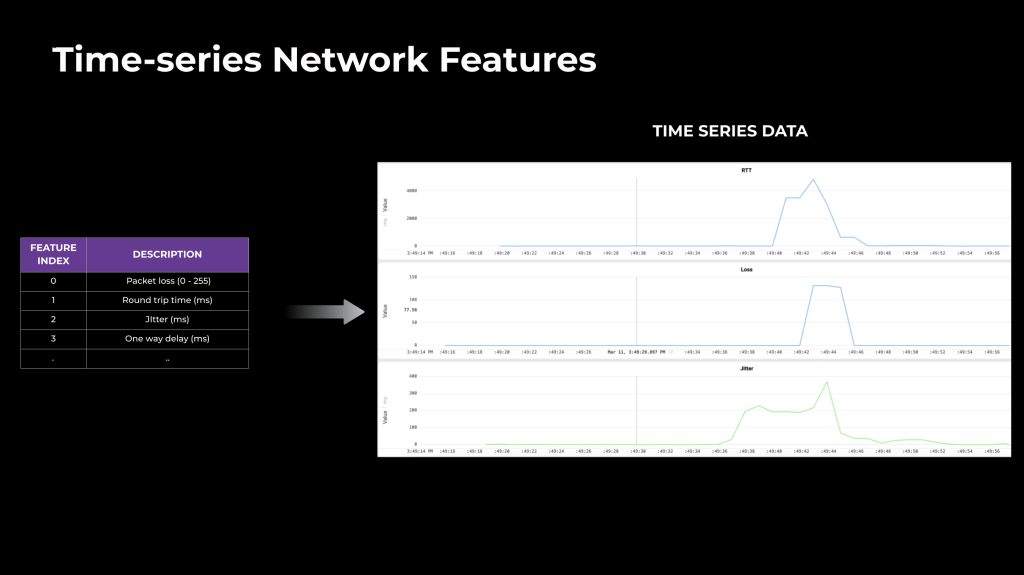
BWE optimization
When the ML model detects random packet loss, we perform local optimization on the BWE module by:
- Increasing the tolerance to random packet loss in the loss-based BWE (holding the bitrate).
- Increasing the ramp-up speed, depending on the link capacity on high bandwidths.
- Increasing the network resiliency by sending additional forward-error correction packets to recover from packet loss.
Network prediction
The network characterization problem discussed in the previous sections focuses on classifying network types based on past information using time series data. For those simple classification tasks, we achieve this using the hand-tuned rules with some limitations. The real power of leveraging ML for networking, however, comes from using it for predicting future network conditions.
We have applied ML for solving congestion-prediction problems for optimizing low-bandwidth users’ experience.
Congestion prediction
From our analysis of production data, we found that low-bandwidth users often incur congestion due to the behavior of the GCC module. By predicting this congestion, we can improve the reliability of such users’ behavior. Towards this, we addressed the following problem statement using round-trip time (RTT) and packet loss:
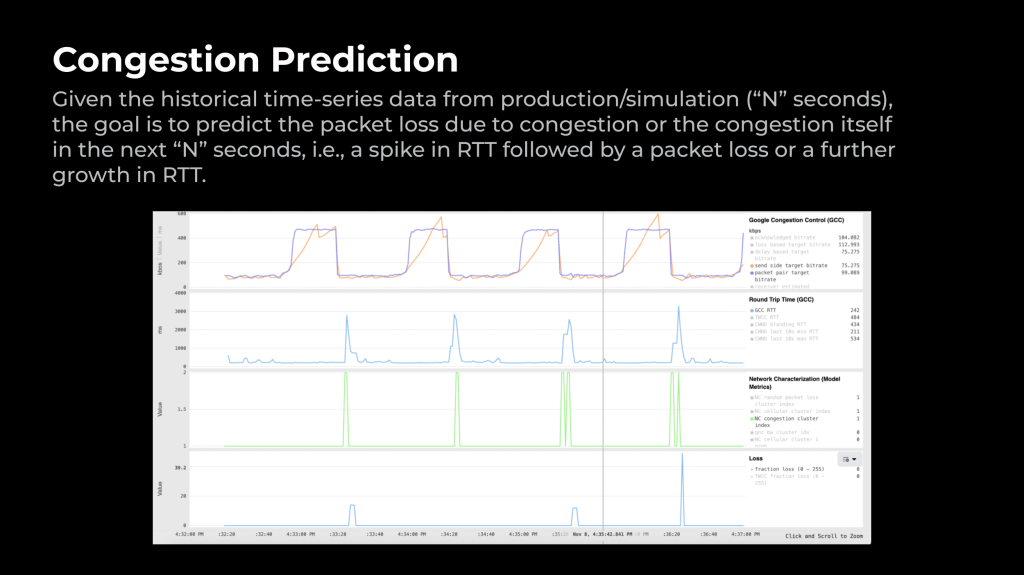
Given the historical time-series data from production/simulation (“N” seconds), the goal is to predict packet loss due to congestion or the congestion itself in the next “N” seconds; that is, a spike in RTT followed by a packet loss or a further growth in RTT.
Figure 7 shows an example from a simulation where the bandwidth alternates between 500 Kbps and 100 Kbps every 30 seconds. As we lower the bandwidth, the network incurs congestion and the ML model predictions fire the green spikes even before the delay spikes and packet loss occur. This early prediction of congestion is helpful in faster reactions and thus improves the user experience by preventing video freezes and connection drops.
Generating training samples
The main challenge in modeling is generating training samples for a variety of congestion situations. With simulations, it’s harder to capture different types of congestion that real user clients would encounter in production networks. As a result, we used actual production logs for labeling congestion samples, following the RTT-spikes criteria in the past and future windows according to the following assumptions:
- Absent past RTT spikes, packet losses in the past and future are independent.
- Absent past RTT spikes, we cannot predict future RTT spikes or fractional losses (i.e., flosses).
We split the time window into past (4 seconds) and future (4 seconds) for labeling.

Model performance
Unlike network characterization, where ground truth is unavailable, we can obtain ground truth by examining the future time window after it has passed and then comparing it with the prediction made four seconds earlier. With this logging information gathered from real production clients, we compared the performance in offline training to online data from user clients:

Experiment results
Here are some highlights from our deployment of various ML models to improve bandwidth estimation:
Reliability wins for congestion prediction
✅ connection_drop_rate -0.326371 +/- 0.216084
✅ last_minute_quality_regression_v1 -0.421602 +/- 0.206063
✅ last_minute_quality_regression_v2 -0.371398 +/- 0.196064
✅ bad_experience_percentage -0.230152 +/- 0.148308
✅ transport_not_ready_pct -0.437294 +/- 0.400812
✅ peer_video_freeze_percentage -0.749419 +/- 0.180661
✅ peer_video_freeze_percentage_above_500ms -0.438967 +/- 0.212394
Quality and user engagement wins for random packet loss characterization in high bandwidth
✅ peer_video_freeze_percentage -0.379246 +/- 0.124718
✅ peer_video_freeze_percentage_above_500ms -0.541780 +/- 0.141212
✅ peer_neteq_plc_cng_perc -0.242295 +/- 0.137200
✅ total_talk_time 0.154204 +/- 0.148788
Reliability and quality wins for cellular low bandwidth classification
✅ connection_drop_rate -0.195908 +/- 0.127956
✅ last_minute_quality_regression_v1 -0.198618 +/- 0.124958
✅ last_minute_quality_regression_v2 -0.188115 +/- 0.138033
✅ peer_neteq_plc_cng_perc -0.359957 +/- 0.191557
✅ peer_video_freeze_percentage -0.653212 +/- 0.142822
Reliability and quality wins for cellular high bandwidth classification
✅ avg_sender_video_encode_fps 0.152003 +/- 0.046807
✅ avg_sender_video_qp -0.228167 +/- 0.041793
✅ avg_video_quality_score 0.296694 +/- 0.043079
✅ avg_video_sent_bitrate 0.430266 +/- 0.092045
Future plans for applying ML to RTC
From our project execution and experimentation on production clients, we noticed that a ML-based approach is more efficient in targeting, end-to-end monitoring, and updating than traditional hand-tuned rules for networking. However, the efficiency of ML solutions largely depends on data quality and labeling (using simulations or production logs). By applying ML-based solutions to solving network prediction problems – congestion in particular – we fully leveraged the power of ML.
In the future, we will be consolidating all the network characterization models into a single model using the multi-task approach to fix the inefficiency due to redundancy in model download, inference, and so on. We will be building a shared representation model for the time series to solve different tasks (e.g., bandwidth classification, packet loss classification, etc.) in network characterization. We will focus on building realistic production network scenarios for model training and validation. This will enable us to use ML to identify optimal network actions given the network conditions. We will persist in refining our learning-based methods to enhance network performance by considering existing network signals.



