X shines as a bustling marketplace of ideas, where every tweet holds the potential to spark conversation and connect brands with their audience. In this sea of chatter, how do we find the whispers that matter? Enter the world of Natural Language Processing (NLP), a beacon that guides us through the digital noise, and the cornerstone of our journey: BERTopic modeling.
What is BERTopic Modeling?
Imagine walking into a library where books are scattered everywhere. Your task is to organize these books so that anyone can find what they’re looking for. BERTopic modeling does something similar with tweets: it arranges them into neat ‘shelves’ or topics based on their content, making sense of the vast information landscape.
BERTopic is the librarian, meticulously organizing tweets into topics so we can see the bigger picture of public discourse.
Unveiling the Tapestry of Text: BERTopic in Practice
Let’s embark on a journey to explore the capabilities of BERTopic, our digital librarian, in organizing a vast library of textual information.
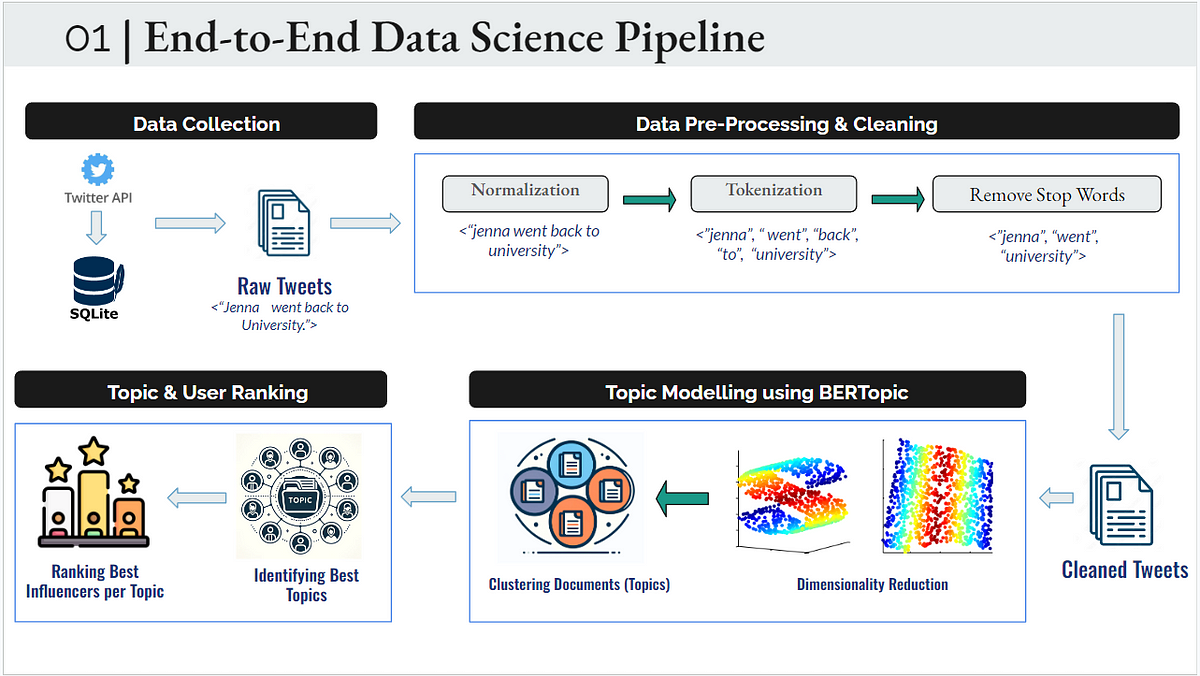
At the core of BERTopic’s operation lies a synergy of advanced components. It starts with the Embedding Model, typically a BERT-based transformer, which reads the text much like understanding the nuanced narrative of each book, converting sentences into rich, high-dimensional vectors. The Vectorizer Model then steps in, fine-tuning the textual representation to ensure that each word’s significance is captured, akin to indexing the key terms in every manuscript for easy retrieval.
The UMAP (Uniform Manifold Approximation and Projection) algorithm acts as the strategic planner, reducing the complexity of these high-dimensional vectors to a more interpretable form, similar to organizing books on shelves by their overarching themes. Following this, the HDBSCAN (Hierarchical Density-Based Spatial Clustering of Applications with Noise) algorithm takes the stage, expertly grouping these organized texts into distinct clusters or topics, much like assigning each set of books to its rightful section in the library.
The CTFIDF (Class-based TF-IDF) model further refines this process, weighing the importance of each word within the topics, ensuring that the most defining terms stand out, just as a librarian would highlight the most notable themes of each book. Lastly, the Representation Model adds a layer of sophistication by enhancing the interpretability of each topic, ensuring that the clusters are not only distinct but also meaningful and easily understandable.
Through this intricate assembly of models and algorithms, BERTopic transforms raw text into a beautifully organized array of topics, each telling its own story, much like a library where every book is meticulously placed, inviting exploration and discovery.
Hyperparameter tuning is essential to optimize the UMAP and HDBSCAN models, ensuring the best configuration for our data analysis. I employed silhouette scores to evaluate the model’s performance, guiding us to the most effective parameter settings for clear and meaningful cluster separation. This approach ensured the models were finely tuned to reveal the underlying patterns and groupings within the X data.
# Build the pipeline with the current parameter settings
stopwords_list = list(stopwords.words('english')) + ['http', 'https', 'amp', 'com', 'gtgtgt', 'please', 'send', 'dm']
vectorizer_model = CountVectorizer(min_df=5,
ngram_range=(1,2),
stop_words=stopwords_list)
embedding_model = AutoModel.from_pretrained('roberta-base')
umap_model = UMAP(n_neighbors= 15,
n_components= 7,
min_dist= 0.1,
random_state= 42)
hdbscan_model = HDBSCAN(min_cluster_size= 100,
min_samples= 40,
gen_min_span_tree=True,
prediction_data=True)
ctfidf = ClassTfidfTransformer(reduce_frequent_words=True)representation_model = KeyBERTInspired()
model = BERTopic(
umap_model=umap_model,
hdbscan_model=hdbscan_model,
embedding_model=embedding_model,
vectorizer_model=vectorizer_model,
representation_model = representation_model,
ctfidf_model=ctfidf,
top_n_words=10,
min_topic_size=100,
language='english',
calculate_probabilities=True,
verbose=True,
nr_topics = 50
)
# Fit the BERTopic model
topics, probs = model.fit_transform(df_tweets_preprocessed['text_preprocessed'])
# Calculate silhouette score
silhouette_avg = silhouette_score(probs, hdbscan_model.labels_)
print(silhouette_avg)
Why BERTopic Matters for Marketers
The magic of BERTopic modeling lies in its ability to uncover what truly engages your audience. It’s not just about the most talked-about topics, but nuanced conversations that could reveal emerging trends, consumer concerns, or even potential brand ambassadors.
For instance, through BERTopic, we might discover a small but passionate conversation about sustainability concerning our product. This insight could steer our marketing strategy towards highlighting eco-friendly practices and tapping into an engaged and relevant audience segment.