





Figure 2: Entity dependency graph (hierarchically from top to bottom)
Bursty write traffic
The data ownership changes result in bursty write traffic to all the entity Source-of-Truth tables of the database. This demands significant write QPS support without causing any data inconsistencies.
Idempotence
With multiple moving parts, different service-level agreements (SLAs) offered by different infrastructure, transient issues are inevitable. The system should retry requests which might result in duplicates. It becomes necessary that the operations should be idempotent.
Support revert
The underlying system should accurately track all the data ownership updates to support the customer requests to revert operations.
Entity cardinality
Entities vary in quantity, with the number of entities to be processed in a request varying significantly, leading to differing processing needs for various entity types. For example, a recruiter might have one or two inboxes, while the number of jobs they manage could range from a few tens to hundreds; the volume of job applications and stored notes can be considerably higher than that of jobs.
To achieve the business requirements and to address the unique challenges, we followed the these five principles:
-
Consistent data – The system should make sure no data is left behind. All the source data should transition over to the destination user.
-
Observable – The system should track all data movement requests and clearly reason about failures and inconsistencies.
-
Durable – The system should auto recover from transient failures. Push for eventual success of the request.
-
Configurable – Enable plug and play. The entity owners should be able to implement the processing interfaces and easily plug into the framework.
-
Scalable – The system should be able to scale to all the entity types irrespective of their cardinality values.
Let’s explore the solution, use cases, and architecture in greater detail.
Why Hybrid
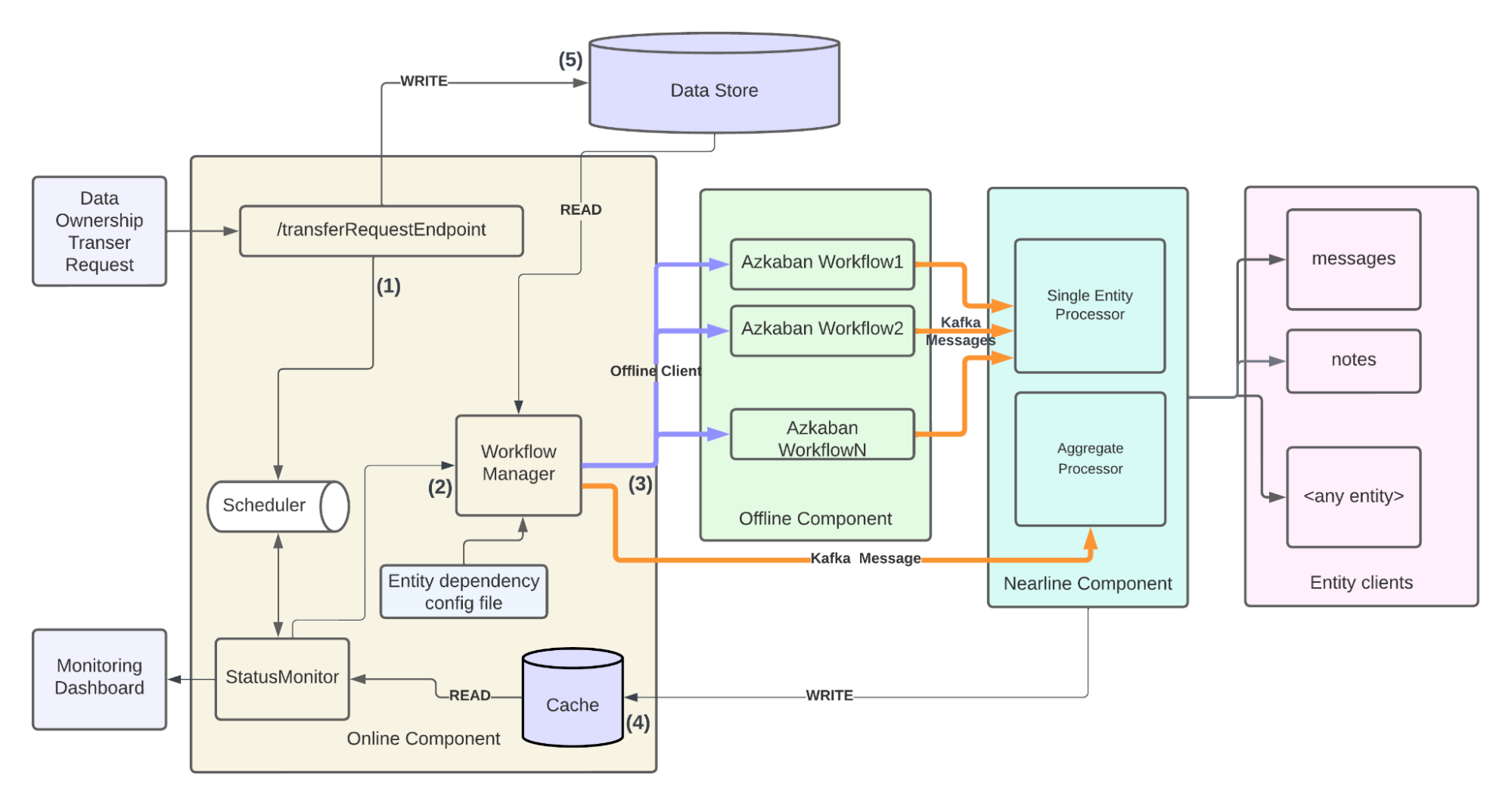
As discussed in the unique challenges section, every entity is different and has its own requirements. Some entities are easier to find and process than others. A framework should be capable of accommodating the processing requirements of present and future entities. A hybrid – offline and nearline components working in tandem – can achieve the requirements in a highly reliable, scalable, and observable manner. Entities that are orders of magnitude larger, and that require heavy processing are advised to scale using offline components. Therefore, we recommend entities that typically take more than 100 seconds to process should onboard to offline, else nearline.
Actors and use cases
Figure 3 below illustrates the data ownership transfer process. To start, customer administrators and LinkedIn support representatives submit data ownership transfers. On failure, reps validate and submit customer escalation requests to Engineering. Then, engineering teams work on new features, new entity onboarding, and troubleshooting issues. The bulk data processing framework which runs on LinkedIn infrastructure executes the workflows and successfully transfers the data ownership of entities as part of LinkedIn Recruiter.



