





On July 5, 2023, Meta launched Threads, the newest product in our family of apps, to an unprecedented success that saw it garner over 100 million sign ups in its first five days.
A small, nimble team of engineers built Threads over the course of only five months of technical work. While the app’s production launch had been under consideration for some time, the business finally made the decision and informed the infrastructure teams to prepare for its launch with only two days’ advance notice. The decision was made with full confidence that Meta’s infrastructure teams can deliver based on their past track record and the maturity of the infrastructure. Despite the daunting challenges with minimal lead time, the infrastructure teams supported the app’s rapid growth exceptionally well.
The seamless scale that people experienced as they signed up by the millions came on the shoulders of over a decade of infrastructure and product development. This was not infrastructure purposely built for Threads, but that had been built over the course of Meta’s lifetime for many products. It had already been built for scale, growth, performance, and reliability, and it managed to exceed our expectations as Threads grew at a pace that no one could have predicted.
A huge amount of infrastructure goes into serving Threads. But, because of space limitations, we will only give examples of two existing components that played an important role: ZippyDB, our distributed key/value datastore, and Async, our aptly named asynchronous serverless function platform.
ZippyDB: Scaling keyspaces for Threads
Let’s zoom in on part of the storage layer, where we leveraged ZippyDB, a distributed key/value database that is run as a fully managed service for engineers to build on. It’s built from the ground up to leverage Meta’s infrastructure, and keyspaces hosted on it can be scaled up and down with relative ease and flexibly placed across any number of data centers. TAO, backed by MySQL, is used for our social graph storage – thus you can find Threads posts and replies directly in that stack. ZippyDB is our key/value counterpart to MySQL, the relational part of our online data stack, and is used for counters, feed ranking/state, and search.
The speed at which we can scale the capacity of a keyspace is made possible by two key features: First, the service runs on a common pool of hardware and is plugged into Meta’s overall capacity management framework. Once new capacity is allocated to the service, the machines are automatically added to the service’s pool and the load balancer kicks in to move data to the new machines. We can absorb thousands of new machines in a matter of a few hours once they are added to the service. While this is great, it is not enough since the end-to-end time in approving capacity, possibly draining it from other services and adding it to ZippyDB, can still be in order of a couple of days. We need to also be able to absorb a surge on shorter notice.
To enable the immediate absorption, we rely on the service architecture’s multi-tenancy and its strong isolation features. This allows for different keyspaces, potentially with complimentary load demands to share the underlying hosts, without worrying about their service level getting impacted when other workloads run hot. There is also slack in the hosts pool due to unused capacity of individual keyspaces as well as buffers for handling disaster recovery events. We can pull levers that shift unused allocations between keyspaces – dipping into any existing slack and letting the hosts run at a higher utilization level to let a keyspace ramp up almost immediately and sustain it over a short interval (a couple of days). All these are simple config changes with tools and automation built around them as they are fairly routine for day-to-day operations.
The combined effects of strong multi-tenancy and ability to absorb new hardware makes it possible for the service to scale more or less seamlessly, even in the face of a sudden large new demand.
Optimizing ZippyDB for a product launch
ZippyDB’s resharding protocol allows us to quickly and transparently increase the sharding factor (i.e., horizontal scaling factor) of a ZippyDB use case with zero downtime for clients, all while maintaining full consistency and correctness guarantees. This allows us to rapidly scale out use cases on the critical path of new product launches with zero interruptions to the launch, even if its load increases by 100x.
We achieve this by having clients hash their keys to logical shards, which are then mapped to a set of physical shards. When a use case grows and requires resharding, we provision a new set of physical shards and install a new logical-to-physical shard mapping in our clients through live configuration changes without downtime. Using hidden access keys on the server itself, and smart data migration logic in our resharding workers, we are then able to atomically move a logical shard from the original mapping to the new mapping. Once all logical shards have been migrated, resharding is complete and we remove the original mapping.
Because scaling up use cases is a critical operation for new product launches, we have invested heavily in our resharding stack to ensure ZippyDB scaling does not block product launches. Specifically, we have designed the resharding stack in a coordinator-worker model so it is horizontally scalable, allowing us to increase resharding speeds when needed, such as during the Threads launch. Additionally, we have developed a set of emergency operator tools to effortlessly deal with sudden use case growth.
The combination of these allowed the ZippyDB team to effectively respond to the rapid growth of Threads. Often, when creating new use cases in ZippyDB, we start small initially and then reshard as growth requires. This approach prevents overprovisioning and promotes efficiency in capacity usage. As the viral growth of Threads began, it became evident that we needed to prepare Threads for a 100x growth by proactively performing resharding. With the help of automation tools developed in the past, we completed the resharding just in time as the Threads team opened up the floodgates to traffic at midnight UK time. This enabled delightful user experiences with Threads, even as its user base soared.
Async: Scaling workload execution for Threads
Async (also known as XFaaS) is a serverless function platform capable of deferring computing to off-peak hours, allowing engineers at Meta to reduce their time from solution conception to production deployment. Async currently processes trillions of function calls per day on more than 100,000 servers and can support multiple programming languages, including HackLang, Python, Haskell, and Erlang.
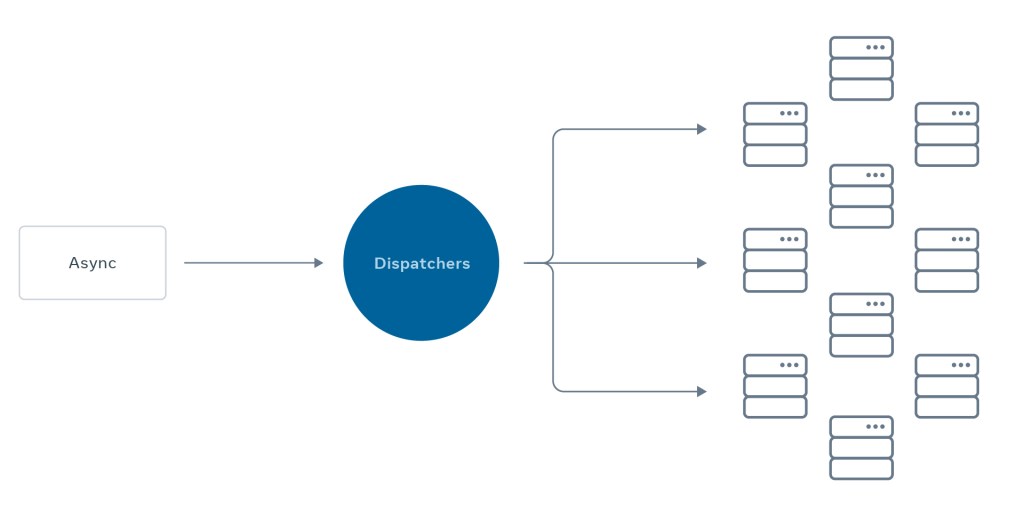
The platform abstracts the details of deployment, queueing, scheduling, scaling, and disaster recovery and readiness, so that developers can focus on their core business logic and offload the rest of the heavy lifting to Async. By onboarding their code in this platform, their code automatically inherits hyperscale attributes. Scalability is not the only key feature of Async. Code uploaded to the platform also inherits guarantees on execution with configurable retries, time for delivery, rate limits, and capacity accountability.
The workloads commonly executed on Async are those that do not require blocking an active user’s experience with a product and can be performed anywhere from a few seconds to several hours after a user’s action. Async played a critical role in offering users the ability to build community quickly by choosing to follow people on Threads that they already follow on Instagram. Specifically, when a new user joins Threads and chooses to follow the same set of people they do on Instagram, the computationally expensive operation of executing the user’s request to follow the same social graph in Threads is conducted via Async in a scalable manner, which avoids blocking or negatively impacting the user’s onboarding experience.
Doing this for 100 million users in five days required significant processing power. Moreover, many celebrities joined Threads, and when that happened millions of people could be queued up to follow them. Both this operation and the corresponding notifications also occurred in Async, enabling scalable operations in the face of a large number of users.
While the volume of Async jobs generated from the rapid Threads user onboarding was several orders of magnitude higher than our initial expectations, Async gracefully absorbed the increased load and queued them for controlled execution. Specifically, the execution was managed within rate limits, which ensured that we were sending notifications and allowing people to make connections in a timely manner without overloading the downstream services that receive traffic from these Async jobs. Async automatically adjusted the flow of execution to match its capacity as well as the capacity of dependent services, such as the social graph database, all without manual intervention from either Threads engineers or infrastructure engineers.
Where infrastructure and culture meet
Threads’ swift development within a mere five months of technical work underscores the strengths of Meta’s infrastructure and engineering culture. Meta’s products leverage a shared infrastructure that has withstood the test of time, empowering product teams to move fast and rapidly scale successful products. The infrastructure boasts a high level of automation, ensuring that, except for efforts to secure capacity on short notice, the automatic redistribution, load balancing, and scaling up of workloads occurred smoothly and transparently. Meta thrives on a move-fast engineering culture, wherein engineers take strong ownership and collaborate seamlessly to accomplish a large shared goal, with efficient processes that would take a typical organization months to coordinate. As an example, our SEV incident-management culture has been an important tool in getting the right visibility, focus, and action in places where we all need to coordinate and move fast. Overall, these factors combined to ensure the success of the Threads launch.



