





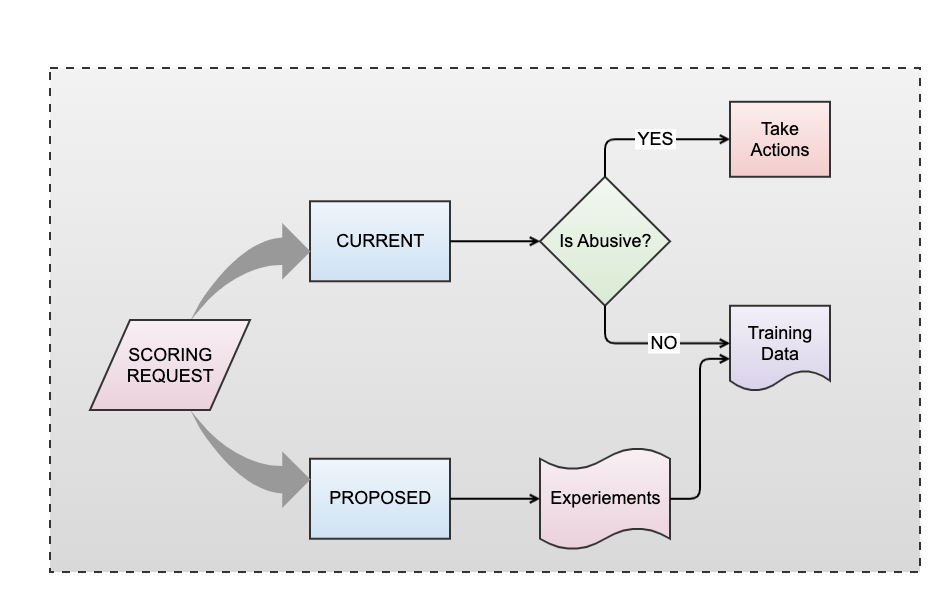
Scoring Modes: CURRENT & PROPOSED
ML model inference: At the heart of our anti-abuse systems lies the formidable capability of ML model inference. The pivotal step is where we harness the power of AI to classify the requests effectively. To do this, we employ a meticulously crafted dependency graph, incorporating various model architectures tailored to our needs.
Our collection of ML models spans a diverse spectrum, from the tried-and-true logistic regression, to powerful tree-based models like XGBoost and isolation forest and cutting-edge deep-learning approaches like sequence models and graph neural networks. Each of these models is custom-tailored and trained to address specific abuse vectors that our system must detect and classify. The result is a symphony of AI-driven insights, each model generating a score and potential classification label. These scores, derived from a multitude of models, become the cornerstone of our decision-making process, enabling us to assess if the incoming request is abusive or not (and also if it violates our policies or terms of service).
It’s essential to note that these ML models are not static entities. Instead, they are continuously evolving, much like the ever-changing landscape of abuse tactics. We train these models periodically, aligning their capabilities with the frequency of shifts underlying abuse vectors. This adaptive approach ensures that our AI is always at the cutting edge, ready to tackle emerging threats. CASAL provides the framework to deploy newer version ML model deployments and perform inference at scale continuously, helping us keep our workflows updated.
Business rules: While ML model inference is a powerful tool, we complement it with another critical element: business rules. These rules bridge AI-driven insights and human expertise, allowing us to make nuanced decisions. Think of them as a set of conditions in a “when-then” format, carefully crafted to consider a combination of features and signals collected during the process. We leverage an open source business rules management system called DROOLS to author them.
Some of these rules draw from historical evidence informed by past encounters with adversarial attacks or known malicious entities. These rules evolve over time, with some designed for immediate impact on ongoing attacks, while others serve as steadfast guardians of our platform’s policies. They are tailored for each abuse vector, ensuring precise classification.
Our team is at the helm of authoring these rules, constantly monitoring our defenses and identifying gaps. We perform rigorous data analysis to craft a new rule when a gap is detected. The power of these rules lies in their speed, as they go into effect immediately without the need for time-consuming deployment changesets. These rules are authored/modified and evolve in a version-based manner. They are asynchronously updated in a datastore which does not require stop-the-world deployment and becomes effective within a few minutes.
The CURRENT and PROPOSED modes we discussed earlier come into play here. In the PROPOSED mode, we define new rules and conduct experiments to validate their efficacy, closely monitoring for exceptions and false positives. This iterative process ensures that our defenses are both robust and agile, capable of responding swiftly to emerging threats. Eventually, after a certain confidence level is reached, we promote these rules to CURRENT mode, wherein we start taking action on the requests.
Experimentation: We need a control plane to launch new defense strategies using newer features, derivations of those features, ML models, and business rules in a controlled environment. We leverage the LinkedIn internal experimentation framework called TREX (Targeting, Ramping, and Experimentation platform) to perform this controlled ramp. TREX allows us to enable targeting, ramping, and experimentation, where a team member can quickly set up an experiment against the targeted member group, ramp the new capability, and quantify its impact in a scientific and controlled manner across all LinkedIn products. TREX allows easy design and deployment of experiments, but it also provides automatic analysis, which is crucial in increasing the adoption of A/B experiments.
Enforcement: Once the scoring requests have traversed the ML model inference and business rule phases, it’s time to determine the appropriate action to take. The wealth of information collected during the process, including scores and classification labels, guides us in making these crucial decisions. For requests that are unequivocally identified as abusive and violate our platform policies, we take immediate action. This might involve enforcing challenges (e.g., CAPTCHA) to distinguish between a bot or human, issuing warnings, sending the entity to human review queue to perform further manual analysis, and in severe cases restricting the account. The aim is not only to protect our members but also to maintain the integrity of the LinkedIn community.
Conversely, when a request is classified as non-abusive with high confidence, we allow it to proceed without interference. Striking the balance between proactive defense and member experience is at the core of our approach.
Tracking: Tracking and monitoring the decisions made within our anti-abuse systems are integral to our continuous improvement efforts. To achieve this, we leverage Kafka messages, a robust and scalable event streaming platform. Kafka allows us to efficiently record and transmit decision data in real-time along with the blueprint of the scoring request including the features collected, ML model scores, activated business rules, and the final set of actions, ensuring that we maintain visibility into our system’s performance.
These Kafka messages serve as a comprehensive record of our decisions, enabling us to conduct thorough post-analysis, identify patterns, and assess the effectiveness of our defenses. This data-driven approach informs our strategy for further enhancements, ensuring that our systems evolve to stay ahead of emerging threats. We also use this dataset to integrate with our in-house built MLOps platform to monitor the feature drift detection, model scores, anomaly detection, etc.
Human review: While our AI-driven models and business rules are highly effective, we recognize the value of human judgment, particularly in nuanced and complex situations. Human reviewers play a pivotal role in our framework. They are equipped with the expertise to perform manual reviews, diving deep into cases that demand a human touch. When a request falls into a gray area or when there’s uncertainty in the classification, human reviewers step in. They provide essential insights, adding an extra layer of scrutiny to ensure that we strike the right balance between automation and human intervention. This collaborative approach safeguards against false positives and ensures that we make well-informed decisions that uphold our platform’s trust and safety standards.
Labeling: A crucial aspect of our system is the meticulous process of labeling. This involves categorizing cases as “true positives” when the system correctly identifies abusive behavior or “false positives” when the system flags non-abusive behavior incorrectly. Labeling holds immense significance in our quest to maintain the highest standards by helping assess the accuracy and performance of our ML models. We gain invaluable insights into how well our models and rules are functioning. This data-driven evaluation allows us to fine-tune our defenses for optimal results, continually enhancing our ability to detect and combat abusive behavior.
Furthermore, the labeled data plays a pivotal role in driving model refinement. It provides a rich source of information for training our models to adapt to the ever-evolving landscape of abuse tactics and user behavior patterns.
Model training: Leveraging the labeled data generated from the true positives and false positives, we need to establish a process that is a continuous cycle of learning and adaptation. Our ML models are trained to analyze this data, identifying nuances and patterns that might escape the human eye. By revisiting and refining the models in the offline environment, we ensure that they are equipped to tackle the latest abuse tactics and user behavior trends–enabling us to respond swiftly.
As CASAL is primarily designed for teams to leverage in performing inference in online (REST: sync & async) and nearline (Kafka) environments, we offload the ML model training to be done in offline environments using LinkedIn Azkaban workflow manager & Hadoop clusters. Through offline ML model training, we harness this data to ensure our models remain at the forefront of abuse detection.
Offline ML model training isn’t just about keeping up with the change; it is about optimizing the performance. Through rigorous experimentation and fine-tuning, we aim to maximize the precision and recall of our models. We meticulously evaluate different algorithms, features, and hyperparameters to achieve the best possible results.
Conclusion
LinkedIn’s anti-abuse framework, CASAL, serves as a vanguard against sophisticated adversaries, reinforcing our commitment to creating a secure and respectful environment for professionals to connect, learn, and grow.
CASAL is the result of a collaborative effort between our engineering and AI teams, data scientists, and domain experts. By fostering a culture of cross-functional collaboration and iterative development, we continuously enhance our algorithms and models to adapt to emerging threats and evolving member needs. This collaborative approach ensures that our Trust ML infrastructure remains effective and robust, further strengthening LinkedIn’s reputation as a trusted platform that prioritizes the security and satisfaction of its members.
In this engineering blog post, we have delved into the Trust ML infrastructure at LinkedIn, highlighting its role in reinforcing the company’s reputation as a trusted industry leader. By showcasing the advanced machine learning techniques, real-time risk assessment capabilities, scalability, and collaborative approach to continuous improvement, we have demonstrated how LinkedIn’s engineering efforts in building and optimizing the Trust ML infrastructure contribute to creating a safe and trustworthy platform for our members. LinkedIn solidifies its position as a trusted destination for professionals worldwide through this commitment to engineering excellence.
Acknowledgments
We would like to extend our heartfelt acknowledgments to the dedicated team who have been the driving force behind our anti-abuse platform success. This is a massive collaborative effort of our core team, comprising brilliant minds from various domains, including Anti-Abuse Infra, Anti-Abuse AI, Data Science (DS), Incident Management, Product Management, Content Review, Productive Machine Learning platform (ProML) and beyond. Their relentless commitment to innovation, problem-solving, and a shared vision of creating a safer online space for professionals worldwide has been truly commendable.
I would also like to extend Xiaofeng Wu, Shane Ma, Hongyi Zhang, James Verbus, Bruce Su, Bing Wang, Abhishekh Bajoria, Katherine Vaiente, Francisco Tobon, Jon Adams, Will Cheng, and Kayla Guglielmo for helping review this blog and provide valuable feedback.



