





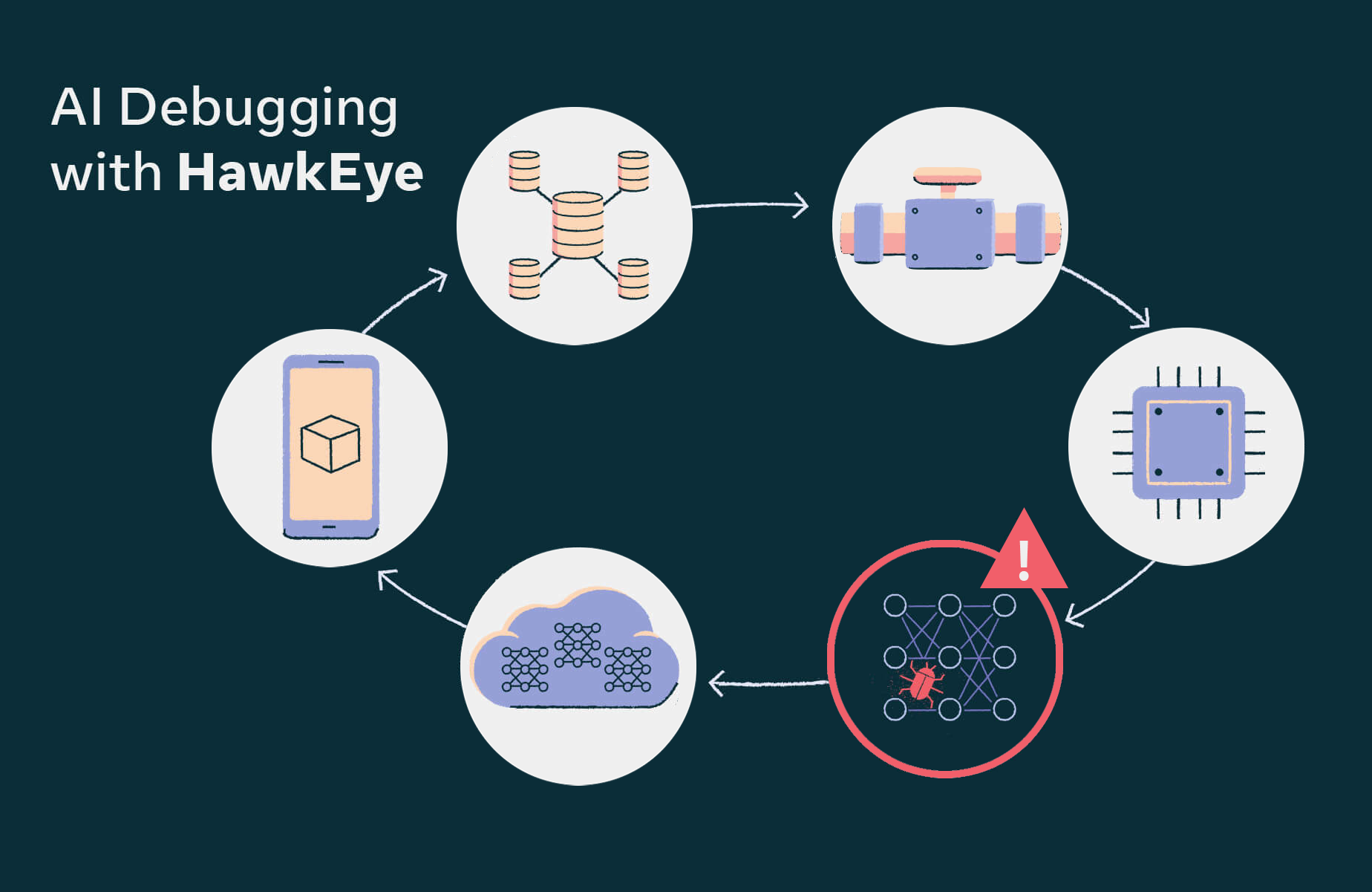
- HawkEye is the powerful toolkit used internally at Meta for monitoring, observability, and debuggability of the end-to-end machine learning (ML) workflow that powers ML-based products.
- HawkEye supports recommendation and ranking models across several products at Meta. Over the past two years, it has facilitated order of magnitude improvements in the time spent debugging production issues.
- In this post, we will provide an overview of the end-to-end debugging workflows supported by HawkEye, components of the system, and the product surface for Meta product and monetization teams to debug AI model and feature issues.
Many of Meta’s products and services leverage ML for various tasks such as recommendations, understanding content, and generating content. Workflows to productionize ML models include data pipelines to get the information needed to train the models, training workflows to build and improve the models over time, evaluation systems to test the models, and inference workflows to actually use the models in Meta’s products. At any point in time multiple versions (snapshots) of a model could be hosted as A/B experiments to test their performance and accuracy.
Ensuring the robustness of predictions made by models is crucial for providing engaging user experiences and effective monetization. However, several factors can affect the accuracy of these predictions, such as the distribution of data used for training, inference-time inputs, the (hyper)parameters of the model, and the systems configuration. Identifying the root cause of any issue is a complex problem, especially given the scale of Meta’s models and data.
At Meta, we created the Prediction Robustness program to innovate on tools and services to ensure the quality of Meta products relying on ML model predictions. HawkEye is the powerful toolkit we built as a part of this effort for the monitoring, observability, and debuggability of ML-based products. HawkEye includes infrastructure for continuously collecting data on serving and training models, data generation, and analysis components for mining root causes. It supports UX workflows for guided exploration, investigation, and initiating mitigation actions.
Our approach to AI debugging
Prior to HawkEye’s development, identifying and resolving issues in production workflows for features and models required specialized knowledge and familiarity with the processes and telemetry involved. Additionally, it required substantial coordination across different organizations. To address these challenges, model and feature on-call engineers, who debug models and features, would utilize shared notebooks and code to do root cause analyses for small parts of the overall debugging process.
HawkEye implements a decision tree that streamlines this process while building the necessary components for continuous instrumentation and analysis layers to build the tree. HawkEye enables users to efficiently navigate the decision tree and quickly identify the root cause of complex issues. As a result, HawkEye has significantly reduced the time spent on debugging complex production issues, simplified operational workflows, and enabled non-experts to triage complex issues with minimal coordination and assistance.

Operational debugging workflows typically begin with an alert triggered by a problem with a key metric for a product, or an anomaly in a model or feature (at serving or training time). Examples of detection mechanisms include model validation failures, model explosions in gradient/loss, prediction anomalies, and shifts in feature distribution. It’s worth noting that a top line anomaly debugging workflow may encompass all of the other workflows. HawkEye supports this workflow by providing guided exploration surfaces layered on top of the necessary components, allowing users to efficiently investigate and resolve issues.
Isolating top-line product issues to model snapshots

The initial step in investigating an anomaly in a product’s top-line metrics is to pinpoint the specific serving model, infrastructure, or traffic-related factors responsible for the degradation. This can be difficult because multiple models might be used for different product and user segments, A/B experiments, or composed predictions. Additionally, model traffic distribution can vary as experiments are scaled up or down.
HawkEye performs analysis and detection to identify models with prediction degradation correlated with the anomaly in the top-line metrics across all experiments. This enables on-call personnel to assess the quality of predictions for all models powering the affected product and/or user segment.
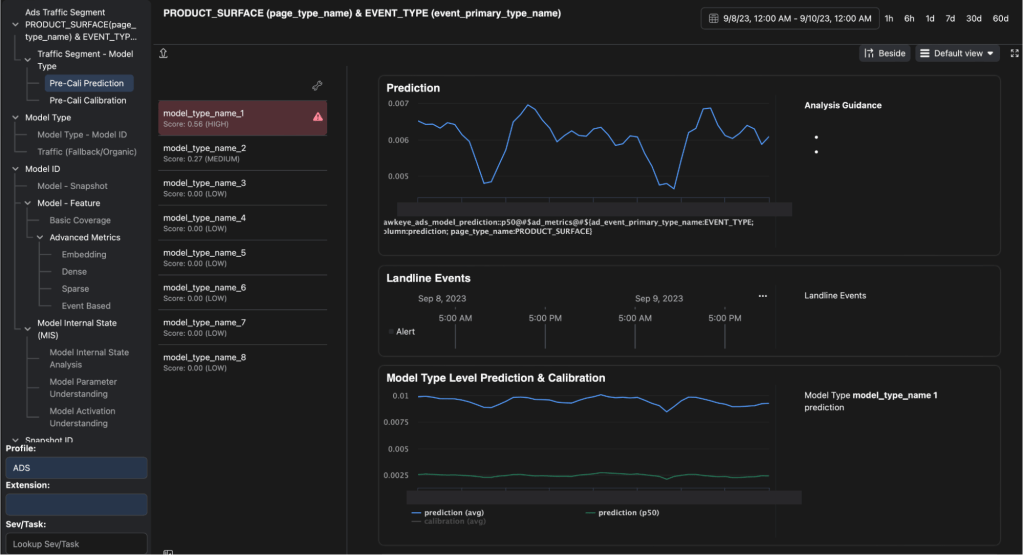
Next, HawkEye enables on-calls to correlate top-line degradation with a timeline of snapshot rollouts for each model. The outcome from this step is typically a small set of suspect model snapshots in serving.
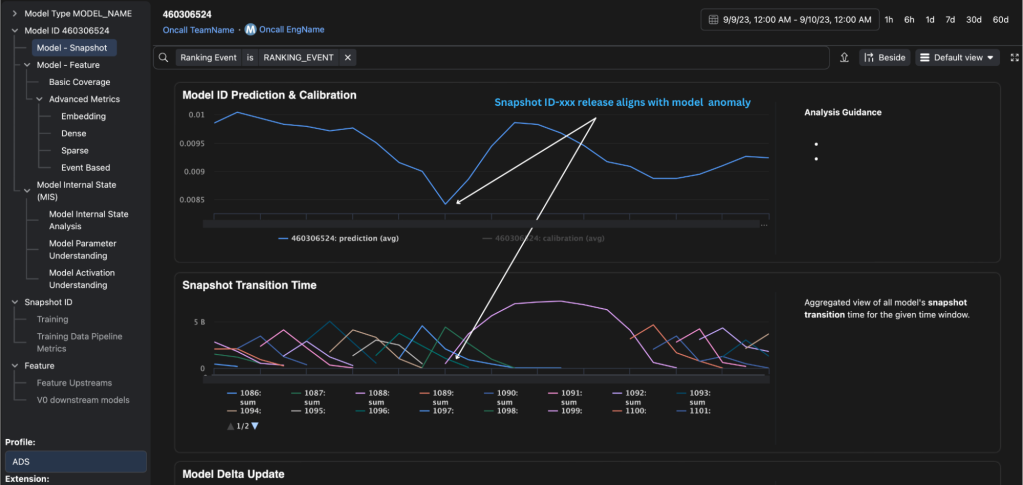
Once a model has been isolated, the next step is to determine if the root cause is a bad snapshot. Rolling back to an older snapshot can provide immediate mitigation, but outdated models can also lead to prediction robustness issues that deteriorate over time. It is essential to identify the underlying cause of a bad snapshot, such as training data or model problems.
Isolating prediction anomalies to features

Serving models can consume thousands of features (each with their own data pipelines) at very high request rates. At such scales, identifying the list of features responsible for prediction anomalies requires real-time analyses of model inputs and outputs. HawkEye uses model explainability and feature importance algorithms to localize prediction changes to subsets of features.
HawkEye samples model inputs and predictions for each serving model and computes correlations between time-aggregated feature distributions and prediction distributions to identify significant correlation structure during periods of degradation. This allows for real-time feature isolation.
In addition, HawkEye computes feature importance changes using feature ablation algorithms on serving model snapshots, which provides a stronger signal than correlational analysis but requires longer processing times due to the need to cover the entire feature distribution hyperspace. When the change in feature importance is significant for a particular feature, it indicates that the feature has a different impact on model predictions in the current snapshot compared to previous snapshots and is a candidate for investigation.
HawkEye presents the on-call with a ranked list of features (or the absence thereof) responsible for prediction anomalies, derived from its model explainability and feature importance analyses. This approach has reduced the time from triage to serving features by several orders of magnitude.
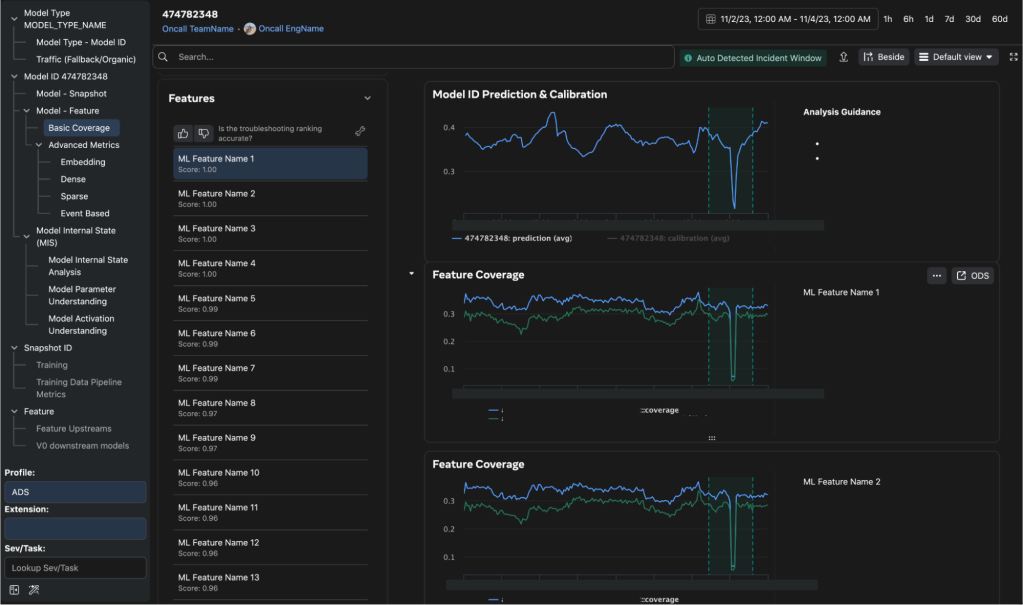
Isolating upstream causes of feature issues

A large-scale data processing setup consists of complex data transformation pipelines (which may include real-time joins), which create features, which are then stored in systems belonging to multiple infrastructure teams. HawkEye tracks the lineage of upstream data and pipelines, keeping track of statistical information about each feature’s upstream data dependencies and transformations that have occurred, including changes to transform code or configurations.
HawkEye facilitates root-cause analysis of feature problems through a visual workflow that moves upstream along the lineage graph and examines the statistics of related lineage nodes. This helps pinpoint the source of a problematic feature by correlating it with upstream data statistics along with a measure of confidence. Without relying on a model anomaly, HawkEye enables investigations into feature upstream issues from feature health alerts, enabling engineers to detect and correct faults before they impact the live models.
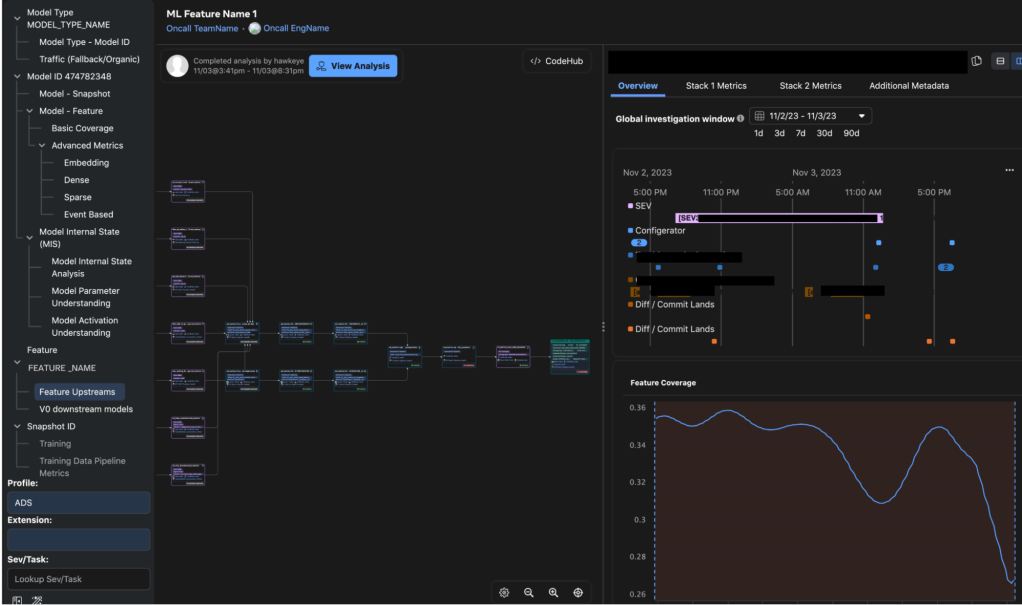
Diagnosing model snapshots

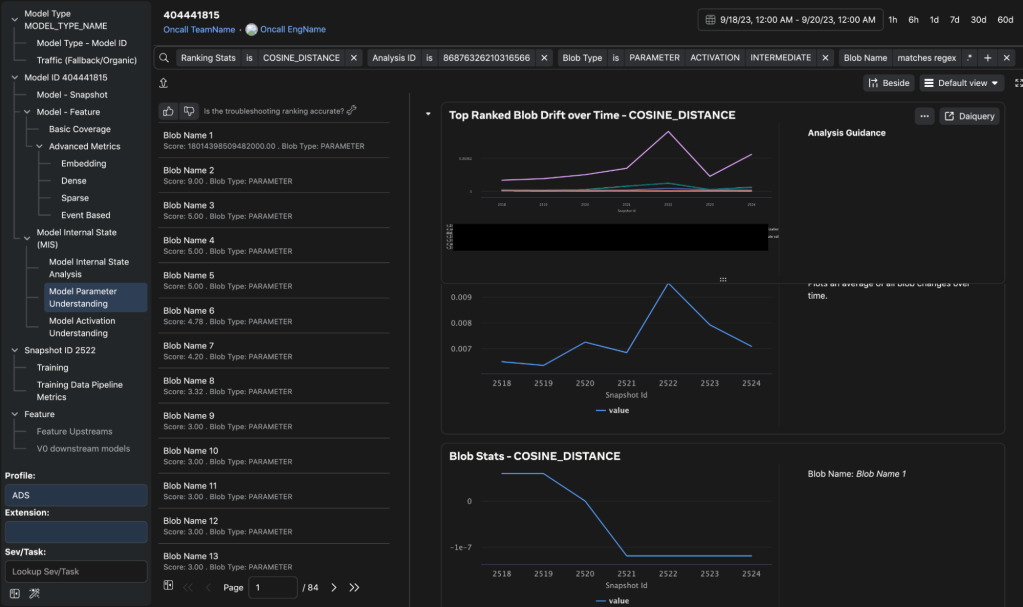
Sometimes prediction errors are not due to the features, but result from issues with the model itself, which are a result of model training (e.g., hyperparameter-, architectural-, or training data-related). To determine whether there is an issue with the model, HawkEye compares the model’s current snapshot (specifically, its weights and biases) with previous snapshots that have been operationally stable. In normal scenarios, model parameters across snapshots show some degree of stationarity. However, significant differences indicate problems with either the training data or loss divergence (e.g., loss or gradient explosion) in the bad snapshot.

When a snapshot is published, HawkEye also runs inference on the snapshot using recent feature data, and captures neuron output and activation tensors in the forward pass. If it finds outputs that are NaNs or extreme values, it uses the activations to walk upstream and downstream on the model graph to associate the problem with feature(s) at the input layer, or the effect on predictions at the output layer. Walking the model graph also enables finding opportunities to improve model architecture (e.g., adding layer normalization, clipping, or other operators).
Analyzing and walking through the large model graph helps identify the cause of bad snapshots quickly and proactively. HawkEye provides model graph visualization with tensor level stats, along with graph walking visualizations. Lowering and post-quantization analyses, as well as analyses while training, are beyond the scope of this discussion.
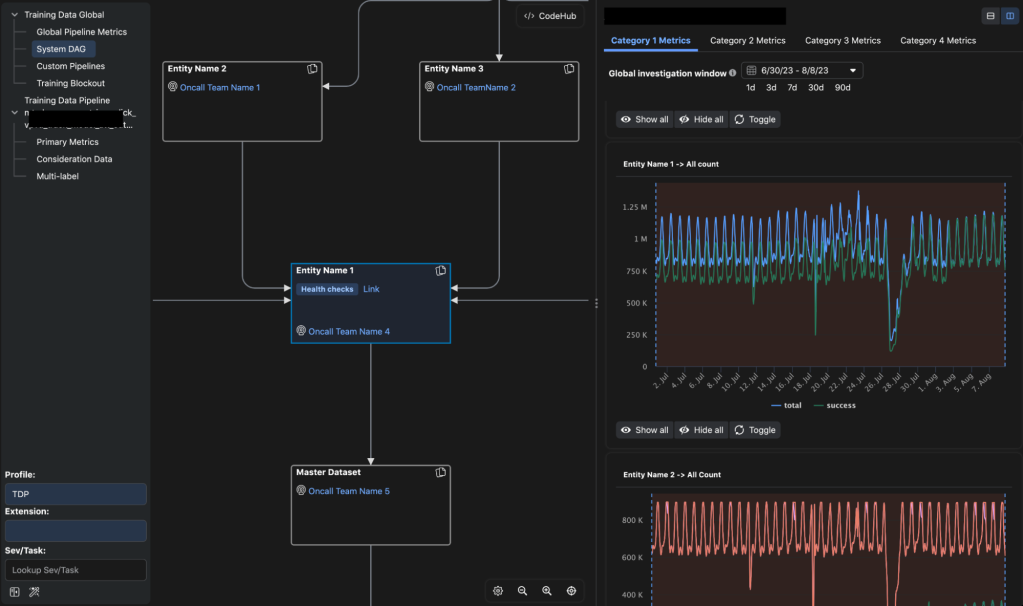
Diagnosing training data issues

HawkEye enables on-calls to easily navigate from a suspect snapshot to the training pipeline that produced it and inspect statistical issues with training data (at a partition granularity) and training-time metrics (e.g., learning curve, loss function evolution). This feature enables the on-call to identify data drift between training and serving label distributions, and anomalies with labels (e.g., label imbalance). Such issues can happen for several hard-to-diagnose reasons, ranging from the complex data pipelines behind training data, to data corruptions. HawkEye provides observability into the upstream data pipelines and their health and helps locate the root cause of bad training data. It also provides quick mitigation capabilities, such as pausing affected pipelines if upstream data is bad, and prevents further production impact due to training snapshots.
Next steps for HawkEye
Moving forward, we will continue to keep track of emerging root causes in production issues, adding detailed analyses to HawkEye workflows and the product surface. We are also piloting extensibility features in the product and backend components, so that product teams can add generic and specialized debugging workflows to HawkEye, while the community benefits from some of these workflows.
Acknowledgements
We would like to thank all current and past members of the HawkEye team and its partners that helped make this effort a success. A special thank you to Girish Vaitheeswaran, Atul Goyal, YJ Liu, Shiblee Sadik, Peng Sun, Adwait Tumbde, Karl Gyllstrom, Sean Lee, Dajian Li, Yu Quan, Robin Tafel, Ankit Asthana, Gautam Shanbhag, and Prabhakar Goyal.



