






- The key to developer velocity across AI lies in minimizing time to first batch (TTFB) for machine learning (ML) engineers.
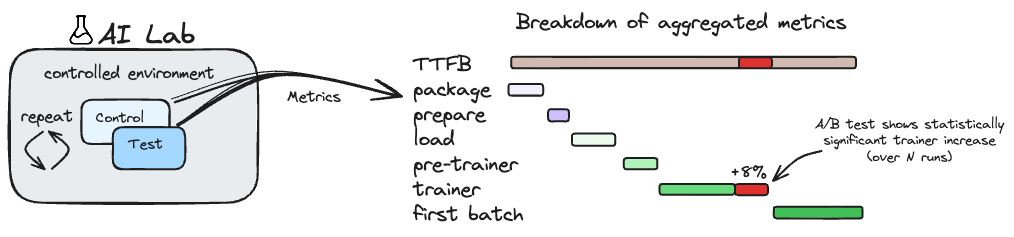
- AI Lab is a pre-production framework used internally at Meta. It allows us to continuously A/B test common ML workflows – enabling proactive improvements and automatically preventing regressions on TTFB.
- AI Lab prevents TTFB regressions whilst enabling experimentation to develop improvements. For example, during the rollout of the open source Python Cinder runtime, AI Lab was used to yield a 2x increase on original TTFB improvements, reducing TTFB by up to 40%.
Time to first batch (TTFB), the delay from when a workflow is submitted to the training job’s first batch, plays an important role in accelerating our machine learning (ML) engineers’ iteration speeds. Essentially, TTFB is the time elapsed from the moment you hit the “start” button on your ML model training to the point when the first batch of data enters the model for processing. TTFB influences the overhead for all ML training jobs and is essentially the moment when developers first get a signal on their job.
By minimizing TTFB we’re unblocking our ML engineers, increasing the number of iterations they can do per day, and improving the overall speed of innovation at Meta.
Supporting TTFB across Meta requires a scalable offering to not only enable proactive improvements on this valuable metric, but also keep it healthy autonomously. To this end we’ve created AI Lab, a pre-production TTFB signal generation tool which empowers infra owners to ship new changes with high confidence, reducing TTFB by up to 40%. This, coupled with automatic prevention of regressions keeps ML engineers moving fast across Meta.
Optimizing TTFB helps ML engineers move fast
The overhead induced from TTFB is on the critical path for most ML development. It is composed of components like config validation, feature pre-processing, and infra overhead (like queuing for capacity). Optimizations to components of TTFB can even impact the entire training cycle of some models. At Meta’s scale, the metric value of TTFB often subtly changes as developers iterate on their model, launcher, or architecture.
To get and keep ML engineers moving fast, two things are required:
- Offensively improve TTFB: We need an intuitive, easy-to-use experimentation framework that allows users to quantify the impact of their changes, enabling fast iteration, and impact certification of new features, empowering infra owners to ship new changes with high confidence.
- Defensively prevent regressions on TTFB: We need continuous regression prevention that tests the latest changes in a low-noise environment, whilst providing a way to monitor, detect, and prevent regressions from affecting ML engineers in the first place.
Introducing AI Lab
AI Lab is a specialized pre-production framework in which we continuously execute common ML workflows as an A/B test to accurately measure the impact of recent changes on metrics like TTFB. Built on top of the same systems as MobileLab, AI Lab automatically defends TTFB by preventing regressions prior to release and enables offensive TTFB improvements opportunistically as an experimentation framework.
Building AI Lab presented unique challenges. Because GPU capacity is such a precious resource, we had to ensure we were a net positive to capacity usage across Meta. We took care to work with partners on shrunk models and simple configurations like some that could run on only CPUs, but still prevent the regressions that would regularly tie up GPUs. To this end, we created an auto-shrinker that aims to ensure tests run the same code / configurations as production; except consume less compute resources. It does things like reduce the number of training iterations and model size, even enabling more deterministic behavior. These tests often run in <10 minutes, which is beneficial for developers iterating on potential TTFB changes. We also needed a holistic strategy to scale to the size of Meta, something we’ll cover in a later section.
Let’s jump into a real example for how we can leverage a tool like AI Lab to reduce TTFB.
Reducing TTFB with the Python Cinder runtime and AI Lab
Meta’s open source Python Cinder runtime brought with it up to a 40% improvement in TTFB thanks to the aggressive lazy imports. Here, we see the true utility of a framework like AI Lab and how it was used to facilitate this sweeping change.
Offensively
We can leverage AI Lab instead of experimenting on real ML engineers’ workflows that may require days or weeks of turnaround to validate a performance hypothesis. With AI Lab, in less than an hour, we’re able to accurately test and measure the impact of a proposed Cinder version on TTFB across a comprehensive set of representative ML scenarios.
In practice, developers turned this into an iteration loop to test further optimizations and fine-tune Cinder, yielding a 2x increase on the original TTFB improvements they were seeing. For example, initially in profiles with Cinder enabled engineers found that up to 10% of the execution time was spent in a workflow to just pretty print. Turns out, the method of memoization used caused a repr() to happen on an underlying data structure, which just so happened to be huge in typical ML scenarios. Instead, they made an object wrapper on this underlying data structure and made memoization comparisons using the object identities instead.
AI Lab verified the improvement, enabling them to proceed with rolling out the change.
Defensively
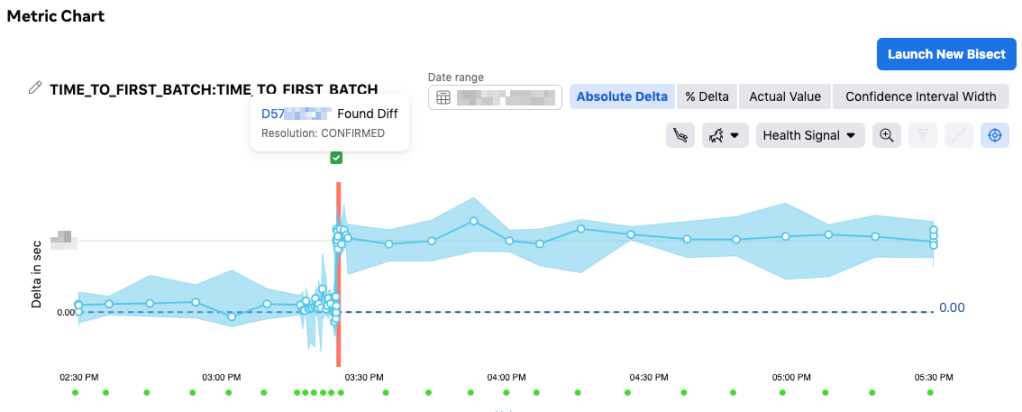
Around when Cinder began rolling out, a regression just so happened to occur that was completely unrelated to the rollout. In this new regression, an engineer added some logging that they believed was being done asynchronously. Unbeknownst to them, the call was actually blocking due to one of the nested clients they required being synchronous. AI Lab leveraged Incident Tracker and automatically attributed the regression down to the specific change. The change author of the regression was notified shortly afterwards, reverting their change before the release went out to production.
Thanks to AI Lab, the engineers working on Cinder never had to worry about a TTFB regression occurring in the same release they rolled out in, avoiding a potential rollback.
How to achieve prevention at Meta’s scale
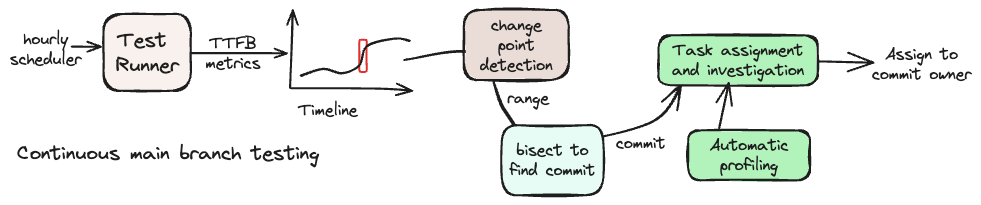
We want to give accurate TTFB signals as early as possible in the development cycle, but it’s infeasible to benchmark all ML scenarios for every change made by every engineer at Meta. Instead, similar to predictive test selection, we establish a limit on capacity used and set out to find as many regressions/improvements as early in the development cycle as possible. In practice, this means:

- O(Code Changes): Running relevant, effective, and computationally efficient (often CPU-only) AI Lab tests on prospective changes before they are even reviewed.
- O(Releases): Running a more holistic set of AI Lab tests prior to release and performing a bisect-like attribution process to find the root cause.
- Attribution in this manner is highly effective and efficient; it serves as a great fallback when we must run more computationally intensive tests to find a certain regression.
Should we find a statistically significant change per a t-test, we perform additional checks before marking it as a regression/improvement:
- Run confirmation runs to confirm we confidently reproduce the expected regression/improvement.
- Ensure the size of the regression/improvement is above a dynamic threshold based on the standard deviation of the test and a tuned receiver operating characteristic. For example, a partner may require <1 false positive per week, which sets the threshold for our tests to find as many true positives as possible whilst staying below that.
Inviting industry collaboration
While AI Lab is an internal-only tool at Meta, we would love to hear from members of the community who may be running similar platforms. Synthetic signal production is a boon to both developers and users. When developers can rapidly evaluate a hypothesis, and users can experience fewer regressions, it speeds up AI innovation across the industry. We’d love to collaborate with the industry to explore more ways we can improve on tools like AI Lab and optimize more metrics like TTFB.
Acknowledgements
AI Lab was made possible due to the foundational work of MobileLab. As we aim to scale past TTFB, we look forward to tackling AI efficiency metrics too with ServiceLab. We’d like to thank members of the AI Training Orchestration team for helping us build AI Lab and all of our users for leveraging the product to keep improving TTFB.



