





Co-authors: Arjun Mohnot, Jenchang Ho, Anthony Quigley, Xing Lin, Anil Alluri, Michael Kuchenbecker
LinkedIn operates one of the world’s largest Apache Hadoop big data clusters. These clusters are the backbone for storing and processing extensive data volumes, empowering us to deliver essential features and services to members, such as personalized recommendations, enhanced search functionality, and valuable insights. Historically, deploying code changes to Hadoop big data clusters has been complex. As workloads and clusters grow, operational overhead becomes even more challenging, including rack maintenance, hardware failures, OS upgrades, and configuration convergence that often arise in large-scale infrastructure.
To help smooth our deployment experience, we built a rolling upgrade (RU) framework. Our RU framework ensures that our big data infrastructure, which consists of over 55,000 hosts and 20 clusters holding exabytes of data, is deployed and updated smoothly by minimizing downtime and avoiding performance degradation. The framework incorporates proactive measures to monitor critical events, provides deployment insights, and issues proper notifications to enable seamless deployments. As a result, the framework significantly reduces the need for manual intervention by introducing automatic pauses and resumes of the deployments based on multiple factors, as well as considering maintenance activities and the cluster’s health.
In this post, we’ll explain how we built our RU framework to power a frictionless deployment experience on a large-scale Hadoop cluster, achieving a >99% success rate free from interruptions or downtime and reducing significant toil for our SRE and Dev teams.
Historical deployment challenges
In the past, our approach to deploying big data components relied heavily on Secure Shell Protocol (SSH), which led to a series of challenges for our deployment operations. Scalability was a significant concern, as using SSH for multiple connections simultaneously caused delays, timeouts, and reduced availability. These SSH-based processes consumed resources, negatively impacting our server and service performance.
The potential for incorrect upgrades also became a risk, since the low observability and reduced reliability of the framework could lead to missing blocks, data corruption, and the possibility of an “under-replicated block storm,” where the namenode attempted to replicate data blocks to datanodes needing more replications. All of these contributed to cluster performance degradations and increased client-side latency, often resulting in timeouts during data reads.
The lack of a state data store, detailed reporting, integration with other tools, and orchestration capabilities also imposed significant manual overhead. This made verifying changes and managing complex workflows challenging, as the deployment framework failed to monitor critical metrics like RPCQueueTimeAvgTime for namenode, which needs to be less than 10 milliseconds, that are essential for meeting strict service level agreements (SLAs).
The historical upgrade system couldn’t adapt to architectural changes like the introduction of an observer namenode (Now handling a massive influx of read requests – 150K QPS – from services such as Trino), ZKFC auto-failover, HDFS federation, etc. These limitations impacted our ability to support our Hadoop infrastructure, with over 1 billion file objects for the larger clusters and approximately 600,000 YARN applications running daily, highlighting the need for a more robust and scalable deployment approach for the Hadoop Distributed File System (HDFS).
The new Rolling Upgrade framework
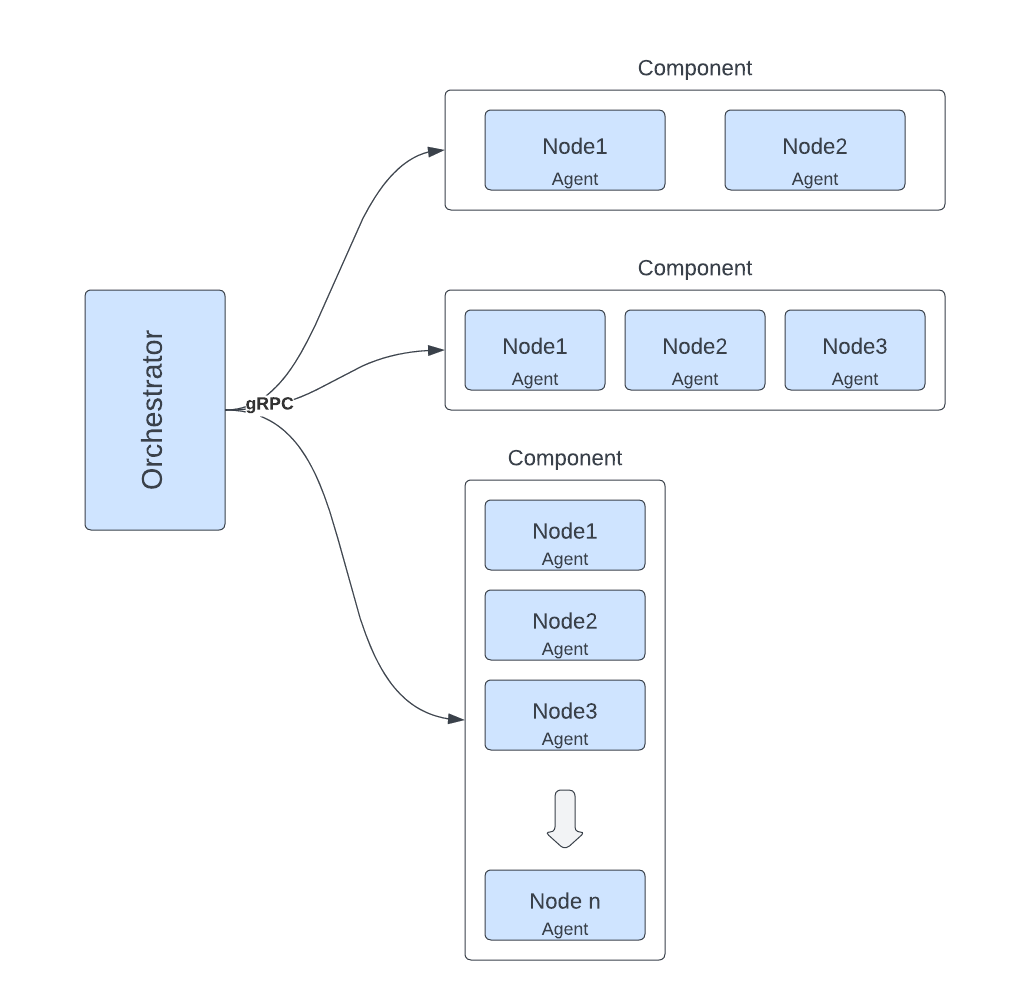
The new RU orchestration design significantly enhanced our big data components deployment process. Utilizing gRPC routines, the orchestrator communicates with agents and guides the process with thorough inspections before and during deployment. Scheduled evaluations periodically check missing blocks, under-replicated blocks, the safe-mode status of the namenode, configuration consistency, cluster capacity, and hardware failures.
The system maintains a robust deployment history, seamlessly integrating with tools like version drift to detect deployed version differences. During cluster degradations, the framework auto-pauses and resumes, mitigating potential intricacies. Highly customizable, it adapts to architectural changes and simplifies the addition of custom validations. Moreover, the system proactively alerts on deployment issues, providing signals with relevant inGraphs metrics, dashboards, and runbooks, reducing manual intervention and enhancing issue resolution efficiency.
Various deployment strategies are now available, including full deployment for all live nodes, canary deployment targeting a specific node percentage, tailored deployment on targeted hosts, and a restart-only mode performing service restarts without executing the actual deployment (Dry Run). The new orchestrator agent design offers versatility and significantly improves the big data deployment process, making it smoother and less prone to issues.
Architecture
The RU framework, written in Golang, consists of the orchestrator and the agent. The orchestrator coordinates the rolling upgrade process by executing the defined commands and managing interactions between multiple agents via gRPC routines, as depicted in Figure 1. The orchestrator’s implementation of the upgrade procedure’s logic performs most of the work.



