





Authors: Ryan Rogers, Subbu Subramaniam, Lin Xu
Contributors: Mark Cesar, Praveen Chaganlal, Xinlin Zhou, Jefferson Lai, Jennifer Li, Stephanie Chung, Margaret Taormina, Gavin Uathavikul, Laura Chen, Rahul Tandra, Siyao Sun, Vinyas Maddi, Shuai Zhang
Content creators post on LinkedIn with the goal of reaching and engaging specific audiences. Post analytics helps creators measure their post performance overall and with specific viewer demographics, so they can better understand what resonates and refine their content strategies. The number of impressions on each post shows how many total views the post has received. Demographic information helps members understand their audience and content performance. However, because the identities of post viewers are not made visible to post authors, there is a need to ensure that demographic information about viewers does not allow post authors to identify specific members that have viewed the post.
A natural approach to ensuring analytics do not reveal the identity of a viewer is to only show aggregates to the post author by certain demographics: company, job title, location, industry, and company size. For example, the post author can only see the top job title of viewers with the corresponding percentage of unique viewers. However, a post author attempting to re-identify post viewers might monitor post analytics such as top job titles, companies, and location as they are updated in real time and attempt to deduce the identity of a member who viewed the post. Hence, after a new viewer on a post, the post author might be able to deduce the job title, company, and location of the member that just viewed the post.
We wanted to better understand whether it was possible to identify members based on these analytics, based on changes in view counts from demographics. We estimate that it is possible for a bad actor to uniquely identify more than a third of weekly active members with three attributes: company, job title, and location. While we are not aware of such an attack occurring on LinkedIn, we are constantly looking for ways to protect our members from increasingly sophisticated attacks by bad actors. Furthermore, when providing only top-20 results in each demographic, we found that it is possible to identify roughly 9% of the initial viewers on a sample of posts. Changing top-20 to only top-5 results dropped this identifiability risk from 9% to less than 2%, but we wanted to reduce this risk even further. This then posed a challenging question: how to protect the privacy of the viewers of posts while still providing useful post analytics to the post author in real-time?
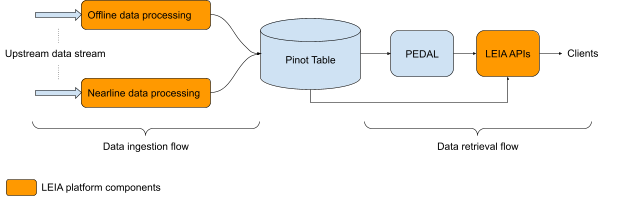
We will detail our approach to add even more safeguards to viewer privacy on post analytics, which is the result of a joint venture across multiple teams at LinkedIn. We are excited to announce the various contributions we have made to provide a privacy-by-design approach to measure and mitigate reidentification risks. This problem poses an interesting juxtaposition between post viewers and post authors that view post analytics: members can be viewers on posts that are not theirs and then those same members can then view analytics on their own posts. Hence, we want to safeguard the privacy of members when they view posts while also providing useful analytics of viewers on their own posts. We will start with a general overview of differential privacy, the gold standard of enforcing privacy for data analytics, which we adopt in post analytics. Next we introduce our privacy service, PEDAL, that works in conjunction with existing infrastructure, such as Pinot, to enable private analytics at scale. Lastly, we discuss the analytics platform at LinkedIn, LEIA, which enables PEDAL to scale across multiple analytics products.
Differential Privacy
To provide a way to safeguard the privacy of viewers while maintaining utility for post authors, we wanted to introduce differential privacy to these analytics. Differential privacy has emerged as the go-to privacy enhancement solution for analytics and machine learning tasks. We say that an algorithm is differentially private if any result of the algorithm cannot depend too much on any single data record in a dataset. Hence, differential privacy provides uncertainty for whether or not an individual data record is in the dataset. To achieve this uncertainty, differential privacy introduces carefully calibrated noise to the results. Differential privacy also quantifies the privacy risk, typically referred to as epsilon, so that the higher the epsilon the more privacy risk the result can have. Hence differential privacy treats privacy risk on a spectrum, rather than a binary choice of there being privacy risk or not.
The privacy risk (epsilon) parameter takes into account multiple decisions that must be made when introducing differential privacy to any task, which includes:
-
The level of privacy protection – granularity of privacy
-
The amount of noise added to each result
-
The number of results returned
The first is referred to as the granularity of privacy, which is typically trying to protect the privacy of all data records of a user. A user might have contributed to multiple data records in a dataset, as in the case of total views because a member can view the same post multiple times. In this case, we would need to consider the changes to analytics when we remove all views from any single member, which can range from 1 to hundreds, although there can be strict limits on how many views any member can contribute. Less stringent privacy baselines have been proposed in the literature, such as event-level privacy which would consider the privacy of each new view in our setting. In our case, we provide top demographic breakdowns based on distinct viewers where each viewer can modify the count of at most one demographic. Note that it is possible for a user, for example, to view a post, change locations, then view the same post again and contribute a distinct view to both locations, but as long as the location remains the same, that user can contribute one distinct view despite viewing the post multiple times. However we will treat the number of total views and distinct viewers as public quantities, not requiring noise.
The next consideration for determining the overall privacy parameter for differential privacy is how much noise is added to each result. Intuitively, adding more noise will ensure more privacy, but we need to better understand how noise will impact the overall product – too much noise would result in strange results that will lead to an untrustworthy product. There are two scenarios that we need to consider when introducing differentially private algorithms. In one case, the data domain is known in advance, which we refer to as the “known domain” setting, and we need only add noise to the counts of these domain elements. This means that we would need to add noise to counts, even if the true count is zero. As (non-differentially private) analytics do not typically give results with zero counts, we need to autofill in the missing zeros prior to adding noise to them. For company size breakdowns, there are only a few possible categories so we can easily fill in the missing values for this case and treat it as a known domain. However adding noise to zero counts might result in positive values leading to false positives in the analytics, meaning that we might show a viewer came from a small company, despite no viewer actually being from a small company. Hence, we introduce thresholds to ensure we show results that are likely to be from true viewers, in order to provide better utility.
In another case, the data domain is not known in advance or can be very large so that adding all possible elements as zero counts in the known domain setting would drastically slow down computation. The “unknown domain” setting then only adds noise to counts that are at least 1, which could reveal, for example, that someone with a particular job title must have viewed the post, despite the noisy count. To prevent this privacy risk, unknown domain algorithms from differential privacy add a threshold so that only noisy counts above the threshold will be shown. The choice of threshold typically depends on the scale of noise that is added as well as an additional privacy parameter, referred to as delta, so that the smaller the delta the larger the threshold but also the better the privacy. The benefit of unknown domain algorithms is that, for example, only companies of actual viewers on a post will be shown, resulting in no false positives, but at the cost of returning fewer results. Some previous applications that used unknown domain algorithms include Wilson, Zhang, Lam, Desfontaines, Simmons-Marengo, Gipson ’20, which used algorithms from Korolova, Kenthadapi, Mishra, Ntoulas ’09, as well as LinkedIn’s Audience Engagements API and Labor Market Insights, which used algorithms from Durfee and Rogers’19.
The last consideration for computing the overall privacy risk is to determine how many results will be shown from a given dataset, in our case, viewers on a post. Although a differentially private algorithm might return a lot of noise to each result, adding fresh noise to each result will allow someone to average out the noise and determine the true result, making noise pointless. This is why the privacy parameter, epsilon, is also commonly called the privacy budget, so there should be a limit on the number of results any differentially private algorithm provides. We want to provide real-time data analytics on posts, so that after each new viewer the analytics are updated and if a post has received no new views we would show the same analytics. To handle this with noise, we then introduce a seed to our randomized algorithms and use the number of distinct viewers on the post as part of the seed. This will ensure consistent results when there are no new viewers, but importantly will not allow someone to repeatedly get fresh noise added to the same analytics despite no new viewers, allowing someone to average out the noise.
Although we can ensure that analytics will remain the same if there are no new viewers, we still want to update the results after each new viewer and there can be thousands of viewers, or more. Hence, the first viewer in the post would appear in potentially thousands of different analytics, updated with each new viewer. Applying differentially private algorithms independently after each new viewer would result in a very large overall privacy budget. We refer to differentially private algorithms that add independent noise to each result as the “one-shot” setting. To help reduce the overall privacy loss, also referred to as the epsilon in differential privacy, we can instead add correlated noise after each new viewer. Luckily there is a line of work in differential privacy on “continual observation” algorithms, originating with Dwork, Naor, Pitassi, and Rothblum ’10 and Chan, Shi, Song ’11 which considers a stream of events, in our case distinct views from members, and returns a stream of counts, in our case demographic breakdowns, with privacy loss which only scales logarithmically with the length of the stream.
Consider the following example where we want to provide a running counter for the number of Data Scientists that have viewed a particular post. Say the stream of views looks like the following where 1 is a Data Scientist viewer and 0 is a different viewer:



