





Authors: Bingfeng Xia and Xinyu Liu
Background
At LinkedIn, Apache Beam plays a pivotal role in stream processing infrastructures that process over 4 trillion events daily through more than 3,000 pipelines across multiple production data centers. This robust framework empowers near real-time data processing for critical services and platforms, ranging from machine learning and notifications to anti-abuse AI modeling. With over 950 million members, ensuring that our platform is running smoothly is critical to connecting members to opportunities worldwide.
In this case study, LinkedIn’s Bingfeng Xia, Engineering Manager, and Xinyu Liu, Senior Staff Engineer, shed light on how the Apache Beam programming model’s unified, portable, and user-friendly data processing framework has enabled a multitude of sophisticated use cases and revolutionized streaming processing at LinkedIn. This technology has optimized cost-to-serve by 2x by unifying stream and batch processing through Apache Samza and Apache Spark runners, enabled real-time ML feature generation, reduced time-to-production for new pipelines from months to days, allowed for processing time-series events at over 3 million queries per second, and more. For our members, this means that we’re able to serve more accurate job recommendations, improve feed recommendations, and identify fake profiles at a faster rate, etc.
LinkedIn Open-Source Ecosystem and Journey to Beam
LinkedIn has a rich history of actively contributing to the open-source community, demonstrating its commitment by creating, managing, and utilizing various open-source software projects. The LinkedIn engineering team has open-sourced over 75 projects across multiple categories, with several gaining widespread adoption and becoming part of the Apache Software Foundation.
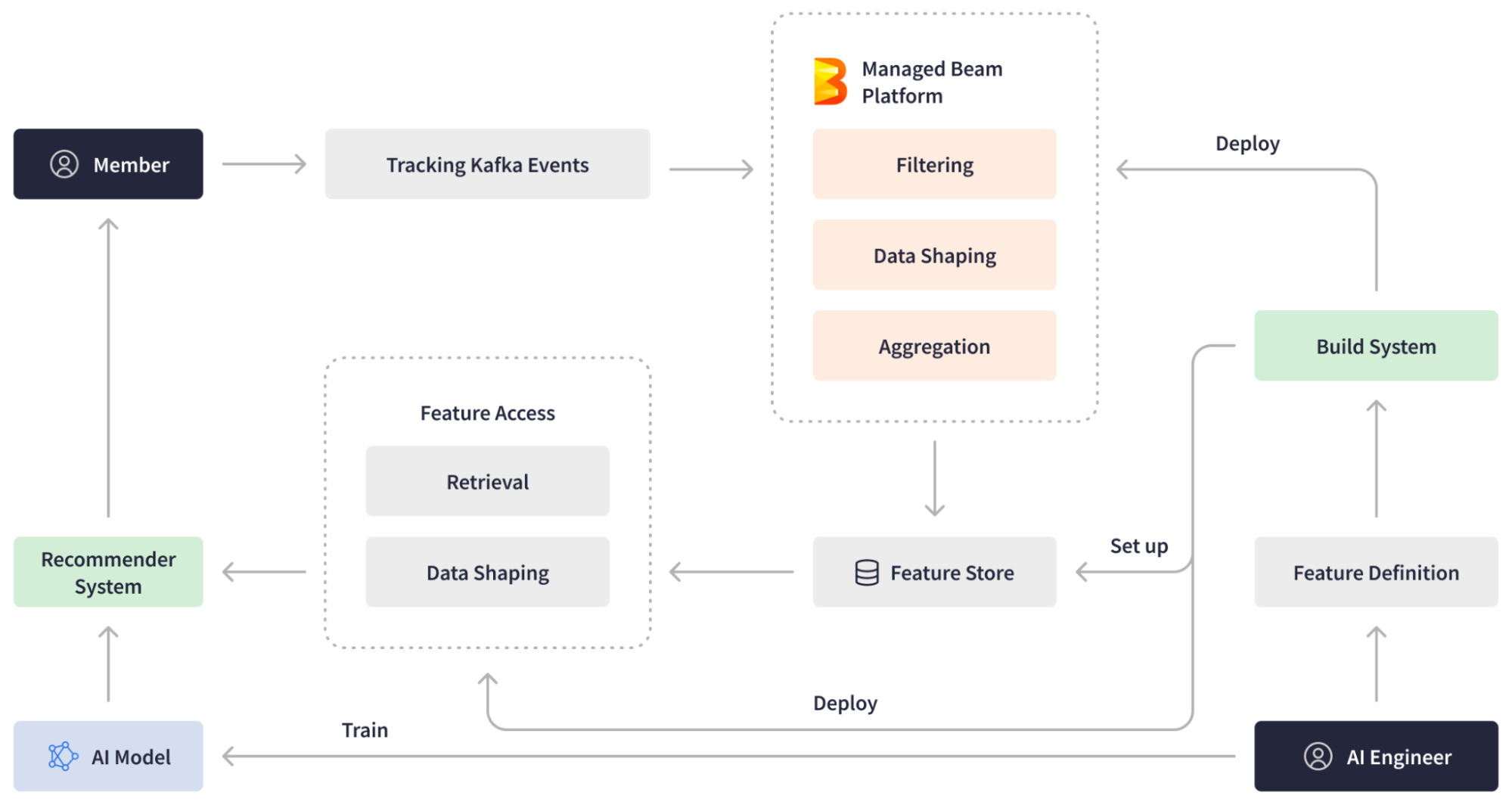
To enable the ingestion and real-time processing of enormous volumes of data, LinkedIn built a custom stream processing ecosystem largely with tools developed in-house (and subsequently open-sourced). In 2010, they introduced Apache Kafka, a pivotal Big Data ingestion backbone for LinkedIn’s real-time infrastructure. To transition from batch-oriented processing and respond to Kafka events within minutes or seconds, they built an in-house distributed event streaming framework, Apache Samza. This framework, along with Apache Spark for batch processing, formed the basis of LinkedIn’s lambda architecture for data processing jobs. Over time, LinkedIn’s engineering team expanded the stream processing ecosystem with more proprietary tools like Brooklin, facilitating data streaming across multiple stores and messaging systems, and Venice, serving as a storage system for ingesting batch and stream processing job outputs, among others.
Though the stream processing ecosystem with Apache Samza at its core enabled large-scale stateful data processing, LinkedIn’s ever-evolving demands required higher scalability and efficiency, as well as lower latency for the streaming pipelines. The lambda architecture approach led to operational complexity and inefficiencies, because it required maintaining two different codebases and two different engines for batch and streaming data. To address these challenges, data engineers sought a higher level of stream processing abstraction and out-of-the-box support for advanced aggregations and transformations. Additionally, they needed the ability to experiment with streaming pipelines in batch mode. There was also a growing need for multi-language support within the overall Java-prevalent teams due to emerging machine learning use cases requiring Python.
The release of Apache Beam in 2016 proved to be a game-changer for LinkedIn. Apache Beam offers an open-source, advanced unified programming model for both batch and streaming processing, making it possible to create a large-scale common data infrastructure across various applications. With support for Python, Go, and Java SDKs and a rich, versatile API layer, Apache Beam provided the ideal solution for building sophisticated multi-language pipelines and running them on any engine.



